第一章:一般概述 (General Overview)
1.1 歡迎來到生物統計的世界!
同學們好!歡迎來到這堂讓許多醫學院與公共衛生學院大一新鮮人又愛又恨的課程——生物統計學 (biostatistics)。
我知道你們在踏入教室前在想什麼:「教授,我是因為不想算數學才來讀醫學/公衛的耶!為什麼我還要學統計?」
先別急著合上課本!在我們的課程裡,沒有無聊的死記硬背,也沒有要你用手算到流淚的複雜公式。相反地,我們要學習的是如何當一名「數據偵探」。
想像一下,未來當你穿上白袍,在診間面對一位高血壓患者時,你正考慮為他開立一種剛上市的降血壓新藥。此時,你的腦海中必須閃過幾個關鍵問題:
- 這個新藥宣稱能顯著降低收縮壓,這是真的有效,還是只是受試者剛好那天心情好而產生的隨機誤差?
- 新藥的效果真的比傳統藥物好嗎?它的副作用發生率是否在安全範圍內?
- 這些藥廠提供的臨床試驗數據,到底是怎麼被收集、整理並得出結論的?
這就是為什麼你需要生物統計學!生物統計學是將統計學的原理與方法,應用在醫學、生物學與公共衛生領域的一門學問。它就像是醫學研究的「解碼器」,幫助我們在充滿不確定性的生命科學世界中,找出客觀的科學證據。這也是現代實證醫學 (evidence-based medicine) 的核心基石。
1.2 統計學的兩大支柱:敘述統計與推論統計
在統計學的大廈中,主要由兩根大柱子支撐著:敘述統計學 (descriptive statistics) 與推論統計學 (inferential statistics)。
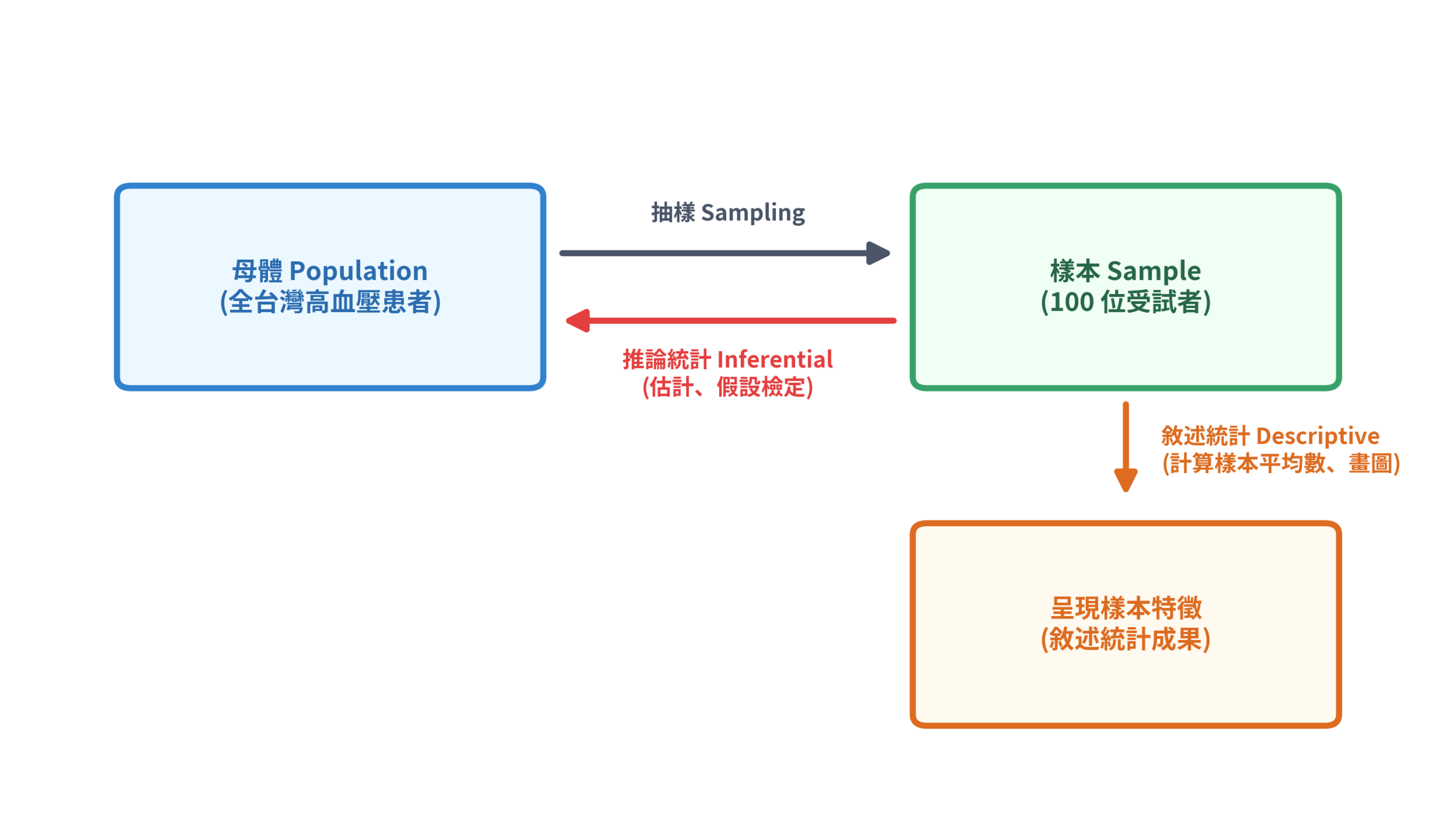
但在介紹這兩大支柱之前,我們先來認識一對在統計界天天吵架、卻又形影不離的經典組合:母體 (population) 與樣本 (sample)。
1.2.1 煮一鍋熱湯:母體與樣本的美味關係
- 母體 (population):指我們研究對象的「全體」。例如「台灣所有成年高血壓患者」。
- 樣本 (sample):指從母體中抽出來進行觀察的「一部分對象」。例如「在某醫學中心隨機抽樣的 100 位高血壓患者」。
💡 教授的美味比喻: 想像你正在煮一鍋超大鍋的豬骨山藥湯(這鍋湯就是母體)。你想知道這鍋湯夠不夠鹹(這就是你想了解的母體特徵,我們稱之為參數 (parameter))。 你不需要把整鍋熱湯通通喝光(這會燙傷,而且就沒湯賣了!)。你只需要拿湯匙把湯攪拌均勻,舀起一小匙喝喝看(這一小匙湯就是樣本,而你嚐出來的鹹度就是統計量 (statistic))。
1.2.2 敘述統計 vs. 推論統計
那麼,這兩大統計方法有什麼不同呢?
- 敘述統計學 (descriptive statistics):
- 任務:整理、簡化與呈現數據。
- 手段:使用圖表(如長條圖、折線圖)、統計指標(如平均數、標準差、中位數)來描繪數據的輪廓。
- 例子:計算這 100 位高血壓病患的平均年齡是 55 歲,其中男性佔 60%。這只是在「描述」我們手頭上有的樣本數據。
- 推論統計學 (inferential statistics):
- 任務:用樣本的資訊去「推測」母體的特徵,並評估推測的可靠程度。
- 手段:估計 (estimation) 與假設檢定 (hypothesis testing)。
- 例子:根據這 100 位病患服用新藥後的血壓變化,利用統計公式推論「全台灣的高血壓病患服用此藥後,平均能降低收縮壓 10 mmHg」的機率有多高。
這兩者的關係可以用下圖來表示:
1.3 我們的得力助手:R 與 RStudio
工欲善其事,必先利其器。現代的生物統計分析不可能再用計算機手算,我們要使用在醫學與公衛界非常流行且強大的統計程式語言——R 語言(本教學採用最新穩定版 R version 4.5.2)。
而為了讓編寫代碼更輕鬆,我們會搭配 R 語言的最佳工作夥伴:RStudio 整合開發環境 (integrated development environment, IDE)。
1.3.1 RStudio 介面四大天王
當你第一次打開 RStudio 時,你會看到介面被切分成四個主要區塊。別慌張,它們各自扮演著重要角色:
- 編輯區 (Source Pane)(左上角):這是你寫劇本的地方。你可以在這裡撰寫 R 程式碼,修改存檔,然後整批執行。
- 控制台 (Console Pane)(左下角):這是 R 的大腦與心臟。你在編輯區執行的代碼會在這裡跑出結果。你也可以直接在這裡輸入單行指令,R 會即時回應你。
- 環境與歷史紀錄區 (Environment/History Pane)(右上角):你的數據暫存庫。所有你匯入的資料集、定義的變項都會顯示在這裡。
- 綜合輔助區 (Files/Plots/Packages/Help Pane)(右下角):你的多功能工具箱。繪製的圖表會顯示在
Plots標籤頁;安裝套件在Packages;遇到不會的函數可以在Help查閱官方說明。
1.4 實戰演練:你的第一個醫學數據分析
現在,讓我們化身為臨床研究人員,親自操作 RStudio 來分析一組模擬的臨床血壓數據。
1.4.1 臨床情境介紹
我們收集了 15 位受試者的基本資料,包括其年齡 (age)、性別 (gender)、收縮壓 (systolic blood pressure, SBP) 與舒張壓 (diastolic blood pressure, DBP)。我們希望透過資料視覺化,觀察這些患者的收縮壓與舒張壓之間是否存在某種關聯,並標記出他們的血壓健康狀態。
本範例將會使用著名的 R 繪圖套件 ggplot2 來繪製一張精美且符合學術論文標準的散佈圖 (scatter plot)。
1.4.2 RStudio GUI 逐步操作指南
步驟一:新建 R 腳本 (R Script)
- 打開 RStudio。
- 點選左上角的
File->New File->R Script。此時左上角會出現一個名為Untitled1的空白編輯區。
步驟二:安裝與載入 ggplot2 套件
在 R 中,繪圖最著名的套件就是
ggplot2。如果你的電腦尚未安裝,請在編輯區輸入以下代碼,並將游標停在該行,按下鍵盤上的Ctrl + Enter(Windows) 或Cmd + Enter(macOS) 執行:install.packages("ggplot2")安裝完成後,我們需要在腳本開頭載入它:
library(ggplot2)
步驟三:輸入模擬數據
- 請將下方的 R 程式碼複製並貼上到你的 R 腳本編輯區中。這段代碼會建立一個名為
bp_data的資料框 (data frame),並根據醫學標準,將受試者的血壓分類為「正常血壓 (Normal)」、「高血壓前期 (Prehypertension)」與「高血壓 (Hypertension)」:
1.4.3 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 建立臨床血壓模擬資料集 (15位受試者)
bp_data <- data.frame(
ID = paste0("P", 101:115),
Age = c(45, 52, 38, 61, 29, 47, 55, 63, 41, 35, 50, 58, 67, 33, 44),
Gender = factor(c("M", "F", "F", "M", "M", "F", "M", "F", "M", "F", "M", "F", "M", "F", "M")),
SBP = c(120, 135, 115, 142, 110, 128, 138, 145, 122, 118, 130, 140, 155, 112, 125),
DBP = c(80, 85, 75, 92, 70, 82, 88, 95, 80, 78, 84, 90, 98, 72, 80)
)
# 3. 根據 SBP 與 DBP 進行血壓狀態分類
bp_data$BP_Status <- factor(
ifelse(bp_data$SBP >= 140 | bp_data$DBP >= 90, "高血壓",
ifelse(bp_data$SBP >= 120 | bp_data$DBP >= 80, "高血壓前期",
"正常血壓")),
levels = c("正常血壓", "高血壓前期", "高血壓")
)
# 4. 使用 ggplot2 繪製散佈圖
# 注意:在不同作業系統中,若中文字型顯示有問題,請依提示更換 base_family 參數
p <- ggplot(bp_data, aes(x = DBP, y = SBP, color = BP_Status)) +
geom_point(size = 4, alpha = 0.8) +
geom_smooth(method = "lm", se = FALSE, color = "#a0aec0", linetype = "dashed", linewidth = 0.5) +
scale_color_manual(values = c("正常血壓" = "#2b6cb0",
"高血壓前期" = "#dd6b20",
"高血壓" = "#e53e3e")) +
labs(
title = "收縮壓與舒張壓之關聯性分析",
subtitle = "模擬 15 位受試者的血壓量測數據",
x = "舒張壓 Diastolic BP (mmHg)",
y = "收縮壓 Systolic BP (mmHg)",
color = "血壓分類狀態"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Linux 系統常用中文字型
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
legend.title = element_text(size = 16, color = "#4a5568"),
legend.position = "bottom",
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 顯示圖表
print(p)💡 字型小提示 (Font Family Tip):
上方程式碼中使用了
base_family = "Noto Sans CJK TC"以利在 Linux 伺服器環境中正確顯示中文。
- 若你使用的是 Windows 系統,請將該行改為
base_family = "Microsoft JhengHei"(微軟正黑體)。- 若你使用的是 macOS 系統,請將該行改為
base_family = "Heiti TC"(黑體-繁)。
1.4.4 統計圖表解讀
當你在 RStudio 中選取上方程式碼並按下 Ctrl+Enter 執行後,右下角的 Plots 頁籤將會呈現如下圖所示的精美散佈圖:
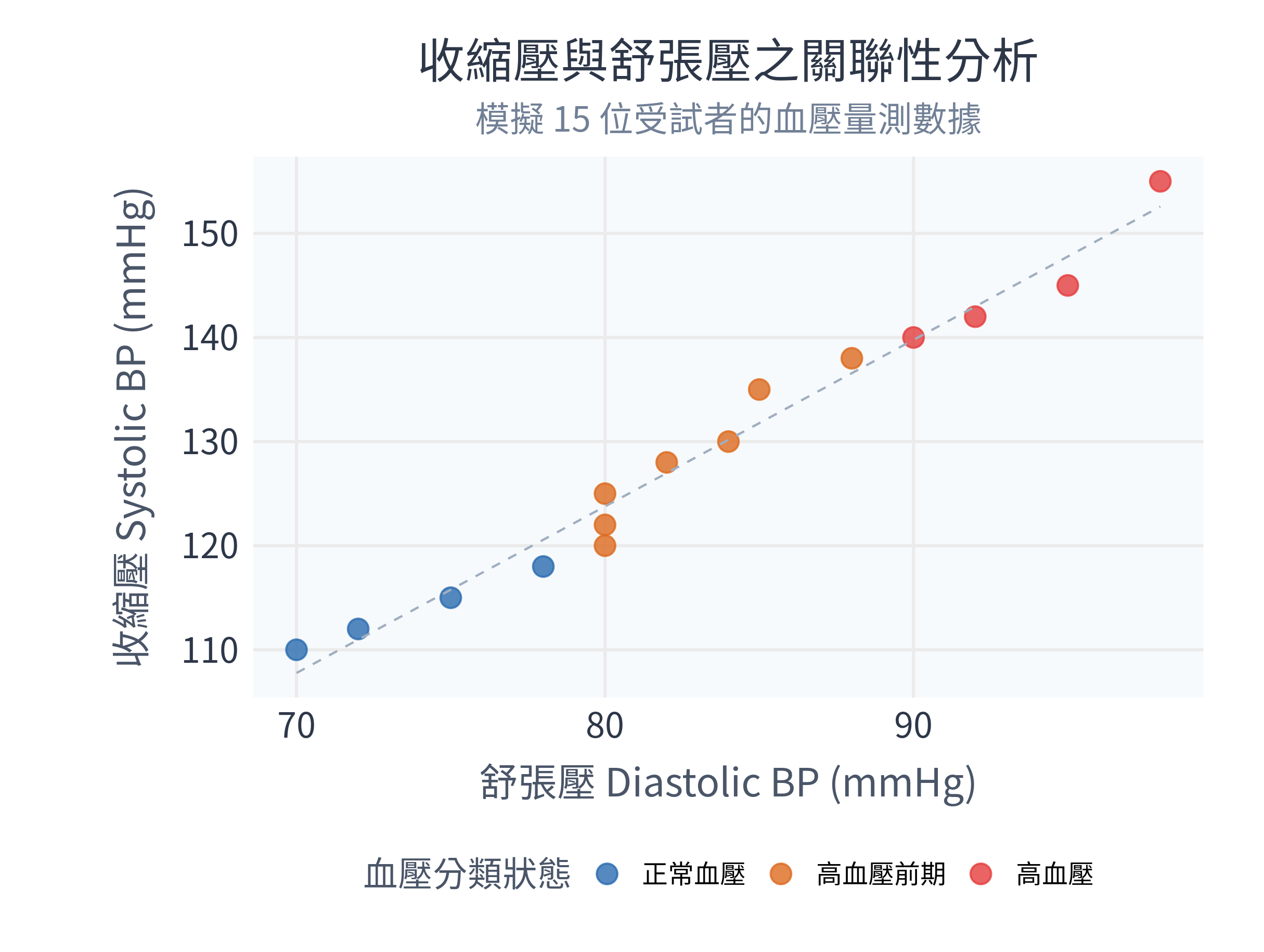
從這張圖中,身為數據偵探的你可以觀察到幾個非常有趣的臨床現象:
- 正相關趨勢:隨著舒張壓(X 軸)的上升,收縮壓(Y 軸)也呈現明顯的上升趨勢。虛線表示的線性迴歸趨勢線也驗證了這一點。
- 群聚特徵:被分類為「高血壓(紅色)」的受試者集中在右上方,而「正常血壓(藍色)」的受試者則聚集在左下方。
- 臨床應用:這樣的視覺化能幫助醫師一眼看出哪些病患處於危險控制區,有助於快速做臨床決策。
1.5 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 生物統計學 | Biostatistics | 將統計學方法應用於醫學、生物學與公衛研究的學問。 |
| 實證醫學 | Evidence-based medicine | 結合最佳臨床研究證據、醫師專業經驗與患者價值觀的醫療決策模式。 |
| 母體 | Population | 研究對象的全體集合。 |
| 樣本 | Sample | 從母體中隨機抽取出來進行實際觀察的一小部分對象。 |
| 參數 | Parameter | 描述母體特徵的數值(通常未知且固定)。 |
| 統計量 | Statistic | 描述樣本特徵的數值(已知但隨樣本而異)。 |
| 敘述統計學 | Descriptive statistics | 整理、摘要與描繪樣本數據特徵的統計方法。 |
| 推論統計學 | Inferential statistics | 利用樣本數據推估母體特徵並進行決策的統計方法。 |
| 估計 | Estimation | 利用樣本統計量去猜測未知母體參數數值的過程。 |
| 假設檢定 | Hypothesis testing | 利用樣本數據來判斷某個關於母體的假設是否成立的決策程序。 |
| 散佈圖 | Scatter plot | 在直角座標系上以點表示兩個變項數值,用以觀察兩者關係的圖表。 |
| 收縮壓 | Systolic blood pressure (SBP) | 心臟收縮時,血液對血管壁產生的最大壓力(mmHg)。 |
| 舒張壓 | Diastolic blood pressure (DBP) | 心臟舒張時,血液對血管壁產生的最低壓力(mmHg)。 |