第六章:估計 (Estimation)
6.1 導言與點估計:從局部窺探全貌
同學們,歡迎來到統計推論(statistical inference)的真正起點。
在前面的章節中,我們已經學會了敘述統計與機率法則。現在,我們要開始解決醫學研究中最核心的挑戰:「我們只有樣本的數據,但我們想知道整個母體的真實情況。」
例如,你想知道「全台灣所有高血壓患者的平均收縮壓」到底是多少。
- 母體參數 (parameter):全台灣高血壓患者的真實平均收縮壓(通常記為 \(\mu\)),這是一個固定但永遠無法精確得知的神秘數字(除非你把全台灣所有高血壓患者通通抓來量血壓)。
- 樣本統計量 (statistic):你隨機抽樣的 100 位患者的平均收縮壓(記為 \(\bar{x}\))。這是一個你可以量得到、算得出的具體數字。
我們用樣本統計量去猜測母體參數的過程,就叫做估計 (estimation)。
估計的方法有兩種:
- 點估計 (point estimation):
- 直接用一個單一的數值來代表我們對母體參數的猜測。
- 例如:你算出來這 100 位患者的平均收縮壓 \(\bar{x} = 135\) mmHg,你就直接說:「我估計全台灣高血壓患者的平均收縮壓 \(\mu\) 就是 135 mmHg。」
- 在統計學上,樣本平均值 \(\bar{X}\) 是母體平均值 \(\mu\) 的無偏估計量 (unbiased estimator),代表如果我們重複抽樣無數次,這些樣本平均值的平均值,會剛好等於真正的母體平均值。
- 區間估計 (interval estimation):
- 因為點估計「一翻兩瞪眼」,猜中的機率極低(畢竟真實值可能是 135.2 或 134.8)。因此,我們改用一個區間來進行估計,並給出我們對這個區間的信心程度。這就是我們常聽到的信賴區間 (confidence interval)。
6.2 抽樣分布與中央極限定理:統計學的超能力
要理解區間估計,我們必須先回答一個哲學問題:「如果我今天重新抽樣一組新的 100 位患者,算出來的平均值還會是 135 嗎?」
答案是:當然不會。這叫做抽樣變異 (sampling variation)。 如果我們不屈不撓地抽樣 10,000 次,每次都算出一個平均值 \(\bar{x}\),把這 10,000 個平均值畫成直方圖,這個圖所代表的分布就叫做平均數的抽樣分布 (sampling distribution of the mean)。
這個抽樣分布有什麼規律嗎?這時,大名鼎鼎的中央極限定理 (Central Limit Theorem, CLT) 就要登場了!
6.2.1 中央極限定理 (CLT) 的奧秘
中央極限定理告訴我們: > 不論母體的分布形狀有多奇怪(可能是偏態、雙峰甚至均勻分布),只要樣本數 \(n\) 足夠大(通常臨床上定義 \(n \ge 30\)),那麼樣本平均值 \(\bar{X}\) 的抽樣分布,都會非常接近常態分布!
這個定理是整個統計推論的基石。它代表著,哪怕我們研究的疾病指標在人群中分佈極度不對稱,只要我們的樣本數夠大,我們依然可以用常態分布的公式來對平均值進行推論!
6.2.2 世紀大混淆:標準差 (SD) vs. 標準誤 (SEM)
這大概是全醫學界不分大一新鮮人還是主治醫師,最常搞混的概念了。請大家務必把下面這段話刻在你的筆電鍵盤上:
🚨 教授的終極警示:SD 與 SEM 的差別
- 標準差 (Standard Deviation, SD):
- 公式:\(s\)
- 臨床意義:描述個體與個體之間的變異程度。例如,這群病人體重的分散狀況。它代表的是「人與人之間的差異」。
- 平均數標準誤 (Standard Error of the Mean, SEM):
- 公式:\(SEM = \frac{s}{\sqrt{n}}\)
- 臨床意義:描述樣本平均值 \(\bar{X}\) 的精密程度(即抽樣誤差的大小)。它代表的是「我們估算出來的平均值到底有多準」。
當樣本數 \(n\) 愈大時,個體間的變異(SD)不會變,但平均數標準誤(SEM)會因為除以 \(\sqrt{n}\) 而變得愈來愈小。這代表樣本愈大,我們對平均數的估算就愈精準。
6.3 區間估計:信賴區間的奧秘
現在我們來談談信賴區間 (confidence interval, CI)。 一個區間估計通常由兩部分組成:區間本身(如 \([130, 140]\))與信賴水準 (confidence level,通常設為 95%)。
⚠️ 觀念大糾錯:什麼是「95% 信賴區間」?
- 錯誤解讀:「有 95% 的機率,母體平均值 \(\mu\) 會落在這個區間內。」(這是不對的!因為母體平均值 \(\mu\) 是一個固定常數,它要嘛在區間內,要嘛不在,機率只有 0 或 1,不存在 95% 機率這回事。)
- 正確解讀:「如果我們從母體中重複抽取 100 個獨立樣本,並依據每個樣本分別建構 100 個信賴區間,那麼大約會有 95 個區間會成功包含真正的母體參數 \(\mu\)。」 簡言之,95% 指的是「這種估計方法的成功率高達 95%」,而不是指某個特定區間的機率。
6.3.1 平均值的 95% 信賴區間計算
當母體標準差 \(\sigma\) 已知時(使用 Z 分數,極罕見): \[95\% \text{ CI} = \bar{x} \pm Z_{0.975} \times SEM = \bar{x} \pm 1.96 \times \frac{\sigma}{\sqrt{n}}\]
當母體標準差 \(\sigma\) 未知時(使用 t 分數,臨床常態): 在現實世界中,我們不可能知道母體標準差,必須用樣本標準差 \(s\) 代替。此時,我們必須使用 Student's t 分布 (t-distribution) 代替 Z 分布: \[95\% \text{ CI} = \bar{x} \pm t_{n-1, 0.975} \times \frac{s}{\sqrt{n}}\]
- t 分布的形狀比標準常態分布稍微矮胖一點,其形狀完全取決於自由度 (degrees of freedom, \(df = n-1\))。
- 當樣本數 \(n\) 愈大,\(df\) 愈高,t 分布就會愈接近標準常態分布。
6.4 二項比例的信賴區間
如果我們的資料是類別型的(例如:患者康復的比例 \(p\)),其點估計量為樣本比例 \(\hat{p} = \frac{x}{n}\)(\(x\) 為成功人數)。 當大樣本時,我們可以使用以下公式計算比例的 95% 信賴區間:
\[95\% \text{ CI} = \hat{p} \pm 1.96 \times \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}\]
6.5 實戰演練:計算患者平均體溫的信賴區間
現在,我們打開 RStudio。假設我們隨機測量了 25 位住院病患的體溫,我們要計算這群病患平均體溫的點估計、標準誤與 95% 信賴區間,並利用 ggplot2 將結果繪製成一張精美的圖表。
6.5.1 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 輸入 25 位病患的體溫數據 (°C)
set.seed(123) # 設定隨機數種子以利重現結果
temp_data <- data.frame(
PatientID = paste0("P", 101:125),
Temperature = round(rnorm(25, mean = 37.1, sd = 0.4), 1)
)
# 3. 計算描述統計與點估計
n <- nrow(temp_data)
mean_temp <- mean(temp_data$Temperature)
sd_temp <- sd(temp_data$Temperature)
# 4. 計算平均數標準誤 (SEM)
sem_temp <- sd_temp / sqrt(n)
# 5. 計算 t 分布下的臨界值與 95% 信賴區間
# qt(p, df) 函數用於反查 t 分布的臨界值。對於雙尾 95%,累積機率取 0.975
alpha <- 0.05
t_crit <- qt(1 - alpha/2, df = n - 1)
margin_error <- t_crit * sem_temp
ci_lower <- mean_temp - margin_error
ci_upper <- mean_temp + margin_error
# 印出計算結果
cat("--- 體溫數據估計結果 ---\n")
cat("樣本平均值 (Point Estimate):", round(mean_temp, 3), "°C\n")
cat("樣本標準差 (SD) :", round(sd_temp, 3), "°C\n")
cat("標準誤 (SEM) :", round(sem_temp, 3), "°C\n")
cat("t 臨界值 (df = 24) :", round(t_crit, 3), "\n")
cat("95% 信賴區間 (95% CI) : [", round(ci_lower, 3), ",", round(ci_upper, 3), "] °C\n")
cat("------------------------\n")
# 6. 建立用於繪製信賴區間的摘要資料框
summary_df <- data.frame(
Variable = "樣本平均值 & 95% CI",
Mean = mean_temp,
Lower = ci_lower,
Upper = ci_upper
)
# 7. 使用 ggplot2 繪製數據點與信賴區間
p_ci <- ggplot() +
# 繪製 25 位患者的個人體溫散佈點 (使用 jitter 避免重疊)
geom_jitter(data = temp_data, aes(x = "個別病患數據分布", y = Temperature),
width = 0.12, size = 3, color = "#4a5568", alpha = 0.6) +
# 繪製樣本平均值紅點
geom_point(data = summary_df, aes(x = Variable, y = Mean), size = 5, color = "#e53e3e") +
# 繪製 95% 信賴區間的誤差棒 (Error Bar)
geom_errorbar(data = summary_df, aes(x = Variable, ymin = Lower, ymax = Upper),
width = 0.2, linewidth = 1.2, color = "#e53e3e") +
labs(
title = "住院患者體溫點估計與 95% 信賴區間",
subtitle = paste0("樣本數 n = 25, 平均數 = ", round(mean_temp, 2), "°C, 95% CI: [",
round(ci_lower, 2), ", ", round(ci_upper, 2), "]"),
x = "",
y = "體溫 Body Temperature (°C)"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
axis.text.x = element_text(size = 16, color = "#2d3748"),
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 顯示並儲存圖表
print(p_ci)
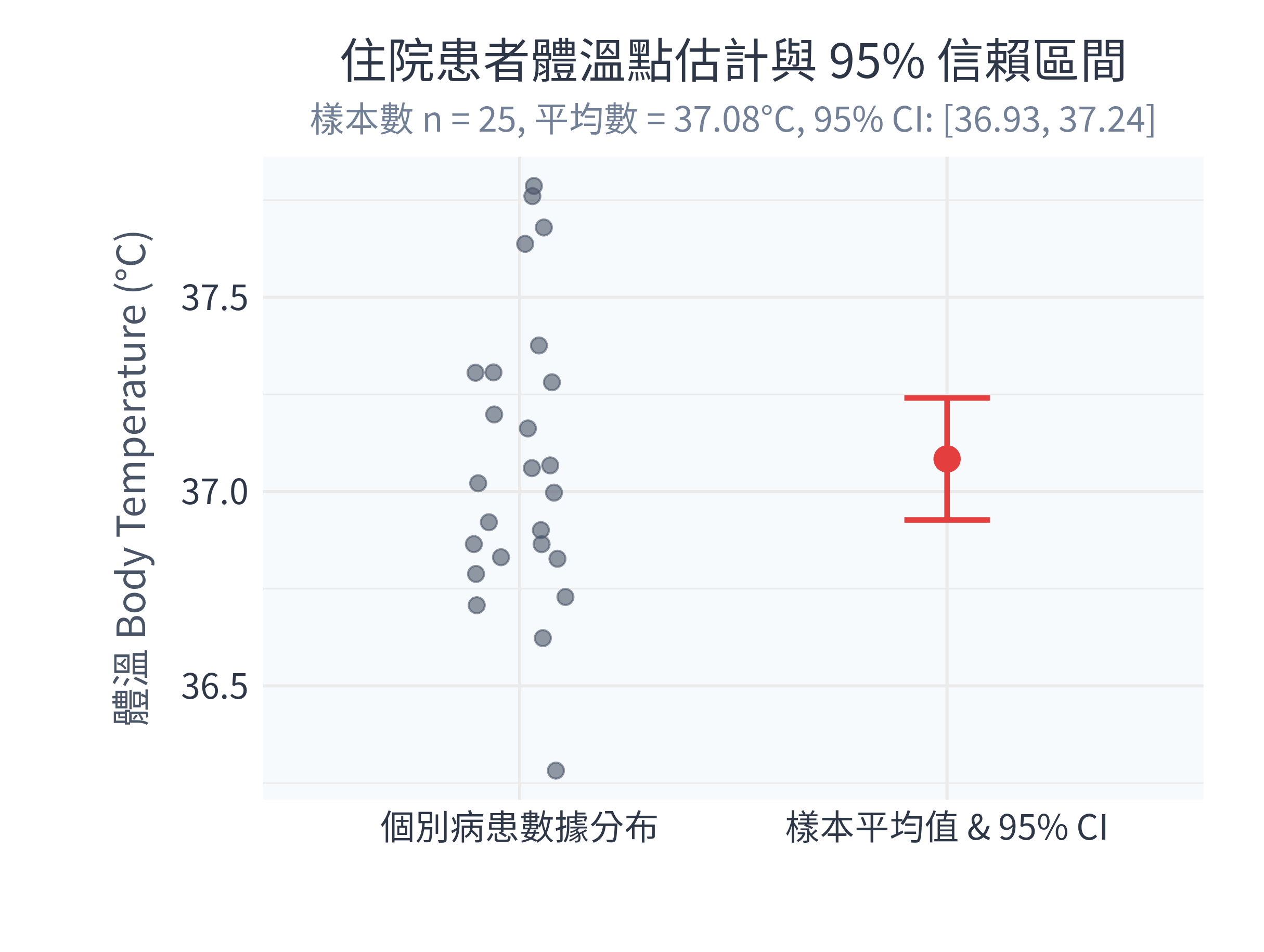
ggsave("figs/temp_ci_plot.png", plot = p_ci, width = 8.1, height = 6.1, dpi = 300)6.5.2 執行結果與圖表解讀
在 R 中執行程式後,控制台會輸出:
--- 體溫數據估計結果 ---
樣本平均值 (Point Estimate): 37.084 °C
樣本標準差 (SD) : 0.3804 °C
標準誤 (SEM) : 0.0761 °C
t 臨界值 (df = 24) : 2.064
95% 信賴區間 (95% CI) : [ 36.927 , 37.241 ] °C
------------------------同時,figs/ 資料夾下會生成以下圖表:
數據診斷分析:
- 點估計與離散度:25 位住院病患的平均體溫是 37.084°C,個體間變異程度(標準差 \(SD\))為 0.38°C。
- 估計的精確度:因為我們的樣本數較小 (\(n=25\)),我們估算出的平均值標準誤 \(SEM = 0.076°C\)。透過 \(t\) 分布公式算出的 95% 信賴區間為 [36.93°C, 37.24°C]。這表示我們有 95% 的信心,這種抽樣區間估計方法能包覆到全院病患真實的平均體溫。
6.6 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 估計 | Estimation | 利用樣本觀測數據推估未知母體參數數值的統計程序。 |
| 點估計 | Point estimation | 用一個單一的統計量數值來作為母體參數估計值的方法。 |
| 無偏估計量 | Unbiased estimator | 若一個統計量的期望值剛好等於被估計的母體參數,該統計量即為無偏估計量。 |
| 區間估計 | Interval estimation | 以一個數值區間及對應的信賴水準來估計母體參數的方法。 |
| 信賴區間 | Confidence interval (CI) | 區間估計所產生的數值範圍,代表可能包含母體參數的範圍。 |
| 信賴水準 | Confidence level | 重複抽樣中,所建構的信賴區間包含真實母體參數的長期成功機率 (如 95%)。 |
| 抽樣分布 | Sampling distribution | 從同一個母體中重複抽取同等樣本數之樣本,其統計量所得出的機率分布。 |
| 中央極限定理 | Central limit theorem (CLT) | 不論母體分佈為何,只要樣本數足夠大,樣本平均值的抽樣分布會趨近常態分布。 |
| 標準誤 | Standard error (SE / SEM) | 樣本統計量(如樣本平均數)抽樣分布的標準差,衡量估計值的精準度。 |
| Student's t 分布 | Student's t-distribution | 在母體標準差未知且樣本數較小時,樣本平均值標準化後所服從的矮胖鐘形分布。 |
| 自由度 | Degrees of freedom (df) | 統計計算中,可以自由變動之數據個數的數量(如 t 分布中 df = n-1)。 |
| 誤差棒 (誤差棒圖) | Error bar | 在圖表上以線段長度表示數據變異程度(如 SD、SEM 或 95% CI)的圖形標記。 |