第二章:敘述統計學 (Descriptive Statistics)
2.1 導言:為什麼不能直接看原始數據?
同學們,上完第一章後,相信你們已經準備好要大顯身手了。
想像一下,你今天參與了一項探討「新型降血脂藥物對臨床患者的效果」的研究。護理師遞給你一張 Excel 表單,上面密密麻麻地寫著 200 位患者的血清膽固醇濃度數值: 220, 195, 240, 188, 310, 215, 205, 250, ...(後面還有 192 個數字)。
主任走過來問你:「所以,這群患者的膽固醇狀況怎麼樣?」
如果你直接把這 200 個數字唸給他聽,我保證主任會在聽到第 10 個數字時,就用眼神把你「超渡」了。
這就是為什麼我們需要敘述統計學 (descriptive statistics)。原始數據(raw data)就像是剛從市場買回來的生肉,你不能直接塞進嘴裡吃,必須經過烹調(整理、摘要、繪圖),才能變成美味好入口的佳餚。本章,我們就要學習如何使用統計指標與圖表,把雜亂無章的數據變成一眼就能看懂的醫學結論。
2.2 中心趨勢的量度:數據的「錨點」在哪裡?
當我們拿到一組數據,第一個想知道的就是:這組數據大約落在什麼地方?這在統計學上叫做中心趨勢 (central tendency) 或位置量度 (measures of location)。
我們常用的中心趨勢指標有四種,它們各有脾氣和適用場景:
2.2.1 算術平均數 (Arithmetic Mean)
這大概是大家最熟悉的指標了,簡稱平均數 (mean)。它的計算方法就是把所有數值加起來,再除以樣本數 \(n\):
\[\bar{x} = \frac{\sum_{i=1}^{n} x_i}{n}\]
- 優點:非常直覺,用到了每一個數據的資訊。
- 致命弱點:極度容易受到離群值 (outlier) 的影響!
💡 教授的幽默提醒: 假設我們班上 5 個同學的月收入分別是 3 萬、3.2 萬、2.8 萬、3.1 萬跟 2.9 萬元,平均收入是 3 萬元。聽起來非常符合大一新生的真實狀況。 這時候,特斯拉創辦人馬斯克(Elon Musk)突然走進教室,說他要加入我們班。馬斯克的月收入假設是 3 億元。如果此時我們重新計算全班的「平均月收入」,答案會暴增到大約 5,000 萬元! 瞬間,我們每個人「平均」都變成了千萬富翁。這合理嗎?顯然不合理。這就是平均數容易被極端值拉偏的壞脾氣。
2.2.2 中位數 (Median)
為了對付馬斯克這種極端值,我們發明了中位數 (median)。 它的定義很簡單:把所有數據從小到大排列,最中間的那一個數字就是中位數。
- 如果樣本數 \(n\) 是奇數,中位數就是第 \(\frac{n+1}{2}\) 個數值。
- 如果樣本數 \(n\) 是偶數,中位數就是最中間兩個數值的平均值,即第 \(\frac{n}{2}\) 與第 \(\frac{n}{2} + 1\) 個數值的平均。
中位數非常「頑強」,對離群值完全免疫。不論馬斯克賺多少錢,中位數依然會守在班上最中間那位同學的薪水(約 3 萬元)附近。
2.2.3 眾數 (Mode)
數據中出現頻率最高的那個數值。在醫學上,我們常用於描述類別資料,例如:患者中人數最多的血型是「O型」(此時 O 型就是眾數)。有時候一組數據可能會有兩個眾數,稱為雙峰分布 (bimodal distribution)。
2.2.4 幾何平均數 (Geometric Mean)
這是一個在生物醫學界非常重要、但非統計背景的人常常忽略的指標! 幾何平均數的計算公式是將所有數值相乘後開 \(n\) 次方根:
\[GM = \sqrt[n]{x_1 \times x_2 \times \dots \times x_n}\]
🔬 為什麼生物醫學界超愛幾何平均數? 在免疫學或病毒學中,像是抗體效價(antibody titer)或是病毒載量(viral load)這類數據,數值的變化通常不是 1, 2, 3 這樣相加的,而是以倍數(如 10, 100, 1000)呈指數成長。這類數據分佈極度不對稱,呈現嚴重的右偏分布 (positively skewed distribution)。 如果直接計算算術平均數,結果會被少數極高的病毒量帶偏;此時,將數據取對數(logarithm)後算平均,再指數還原回來的幾何平均數,才是最能客觀反映真實抗體/病毒濃度的指標。
2.3 離散趨勢的量度:數據的「波浪」有多大?
單單知道「中心」在哪裡是不夠的。
💡 臨床實務警告: 假設加護病房有兩位糖尿病患,他們整天測量下來的「平均血糖值」都是 140 mg/dL。主治醫師可以直接認為兩人的血糖控制得一樣好嗎? 絕對不行!
- 病患甲的血糖非常穩定,整天都在 130 ~ 150 mg/dL 之間微幅波動(變異極小,非常安全)。
- 病患乙的血糖卻像坐雲霄飛車,清晨低到 40 mg/dL(隨時有低血糖休克死亡的危險),下午又飆到 240 mg/dL(嚴重高血糖)。 兩人的平均血糖雖然相同,但病患乙的血糖波動劇烈,正面臨極大的生命危險!
這就說明了,我們除了知道平均值,還必須知道數據的波動範圍,也就是離散趨勢 (measures of spread / dispersion)。
2.3.1 全距 (Range)
最簡單的離散指標,就是最大值減去最小值:
\[\text{Range} = x_{\text{max}} - x_{\text{min}}\]
缺點很明顯:只用了最大跟最小兩個數值,無法得知中間其他數據的變異狀況,且同樣極易受極端值干擾。
2.3.2 變異數 (Variance) 與標準差 (Standard Deviation)
為了衡量每個數據距離「平均值」有多遠,我們使用變異數 (variance, 通常樣本變異數記為 \(s^2\)) 與標準差 (standard deviation, 簡寫為 SD,記為 \(s\))。
樣本變異數的公式為:
\[s^2 = \frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n - 1}\]
而標準差就是變異數的平方根:
\[s = \sqrt{s^2}\]
🙋♂️ 教授,為什麼公式的分母是 \(n - 1\) 而不是 \(n\)? 這在統計學上叫做自由度 (degrees of freedom)。因為我們在算變異數時,已經先借用了「樣本平均值 \(\bar{x}\)」這個資訊,這使得最後一個離差數值不再自由(所有的離差相加必須等於 0)。為了得到對母體變異數的無偏估計 (unbiased estimate),我們必須除以 \(n - 1\)。記住,這不是算術平均,這是統計學的特有規則!
標準差的單位與原始數據相同(例如膽固醇是 mg/dL,標準差單位也是 mg/dL),這讓我們在解釋臨床意義時非常方便。標準差愈大,代表這群患者之間的個體差異愈大。
2.3.3 變異係數 (Coefficient of Variation, CV)
當你想比較兩個單位不同、或者平均值相差極大的數據時,標準差就英雄無用武之地了。此時,我們需要變異係數 (CV):
\[CV = \frac{s}{\bar{x}} \times 100\%\]
例如,你想比較「小鼠體重(平均 30 公克,標準差 3 公克)」與「大象體重(平均 5000 公斤,標準差 200 公斤)」哪一個波動更大?
- 小鼠的 \(CV = (3 / 30) \times 100\% = 10\%\)
- 大象的 \(CV = (200 / 5000) \times 100\% = 4\%\) 結果一目了然:小鼠體重的相對變異程度,其實比大象還要大!
2.4 統計圖表之美:直方圖與箱形圖
除了數字,視覺化的圖表往往能傳達更多訊息。本章我們介紹醫學論文最常見的兩種圖表:
2.4.1 直方圖 (Histogram)
將連續型變項的數值區間切分成好幾個等寬的小區間(組距),再統計落在每個區間的個案數。直方圖能讓我們一眼看出數據的分布形狀(是像鐘形的對稱分布,還是往某邊傾斜的偏態分布)。
2.4.2 箱形圖 (Box Plot)
箱形圖(又稱盒鬚圖)是呈現數據「五數綜合」的視覺神器。這五個數分別是:最小值、第一四分位數 (\(Q_1\))、中位數(\(Q_2\) 或 \(Median\))、第三四分位數 (\(Q_3\))、最大值。
下圖展示了箱形圖的解構:
離群值 (Outlier) o (高於 Q3 + 1.5 * IQR)
|
最大非離群值 ------+------- (上限 = Q3 + 1.5 * IQR 內的最大值)
|
+------- 第三四分位數 Q3 (第 75 百分位數)
| |
|中位 |
| 數 |--- 中位數 Median (第 50 百分位數)
| |
+------- 第一四分位數 Q1 (第 25 百分位數)
|
最小非離群值 ------+------- (下限 = Q1 - 1.5 * IQR 外的最小值)
|
離群值 (Outlier) o (低於 Q1 - 1.5 * IQR)- 箱子的中間線代表中位數。
- 箱子的上下邊緣分別代表 \(Q_3\) 與 \(Q_1\)。箱子的高度就是四分位距 (\(IQR = Q_3 - Q_1\))。
- 往外延伸的「鬍鬚」最長延伸至 \(Q_1 - 1.5 \times IQR\) 與 \(Q_3 + 1.5 \times IQR\)。
- 超出鬍鬚範圍的點點,在統計學上會被定義為離群值 (outlier),需要臨床人員特別注意。
2.5 實戰演練:血清膽固醇數據分析
現在,我們打開 RStudio,對一組 20 位心臟科患者的模擬血清膽固醇數據進行完整的敘述統計分析。
2.5.1 RStudio 操作說明
- 開啟 RStudio,在左上角
File->New File->R Script建立一個新腳本。 - 複製以下 R 程式碼,貼入編輯區。
- 點選程式碼,按
Ctrl+Enter(Windows) 或Cmd+Enter(macOS) 執行。
2.5.2 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 輸入 20 位患者的血清膽固醇數值 (mg/dL)
chol_data <- data.frame(
PatientID = paste0("ID_", 1:20),
Cholesterol = c(220, 195, 240, 188, 310, 215, 205, 250, 190, 225,
235, 175, 260, 280, 200, 218, 230, 245, 290, 160)
)
# 3. 計算中心趨勢量度
mean_val <- mean(chol_data$Cholesterol)
median_val <- median(chol_data$Cholesterol)
# 4. 計算離散趨勢量度
sd_val <- sd(chol_data$Cholesterol)
var_val <- var(chol_data$Cholesterol)
range_val <- range(chol_data$Cholesterol)
diff_range <- diff(range_val) # 最大值減最小值,即全距
cv_val <- (sd_val / mean_val) * 100
# 5. 印出計算結果
cat("--- 膽固醇數據描述統計結果 ---\n")
cat("算術平均數 (Mean) :", mean_val, "mg/dL\n")
cat("中位數 (Median) :", median_val, "mg/dL\n")
cat("標準差 (SD) :", sd_val, "mg/dL\n")
cat("變異數 (Variance) :", var_val, "\n")
cat("全距 (Range) :", range_val[1], "~", range_val[2], " (全距大小 =", diff_range, ")\n")
cat("變異係數 (CV) :", round(cv_val, 2), "%\n")
cat("-----------------------------\n")
# 6. 使用 ggplot2 繪製直方圖並存檔
h_plot <- ggplot(chol_data, aes(x = Cholesterol)) +
geom_histogram(binwidth = 20, fill = "#3182ce", color = "white", alpha = 0.8) +
labs(
title = "心臟科患者血清膽固醇分布直方圖",
subtitle = "模擬 20 位患者之膽固醇數據 (mg/dL)",
x = "血清膽固醇 Serum Cholesterol (mg/dL)",
y = "患者人數 (Frequency)"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
ggsave("figs/cholesterol_hist.png", plot = h_plot, width = 7.4, height = 5.4, dpi = 300)
# 7. 使用 ggplot2 繪製箱形圖並存檔
b_plot <- ggplot(chol_data, aes(y = Cholesterol)) +
geom_boxplot(fill = "#dd6b20", color = "#2d3748", alpha = 0.7, width = 0.3) +
geom_jitter(aes(x = 0), width = 0.05, color = "#2d3748", alpha = 0.6, size = 2) +
scale_x_continuous(limits = c(-0.5, 0.5), breaks = NULL) +
labs(
title = "心臟科患者血清膽固醇箱形圖",
subtitle = "呈現數據之五數綜合與離群值 (mg/dL)",
x = "",
y = "血清膽固醇 Serum Cholesterol (mg/dL)"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
ggsave("figs/cholesterol_box.png", plot = b_plot, width = 5.4, height = 6.1, dpi = 300)2.5.3 執行結果與圖表解讀
當你在 R 控制台執行上述程式碼後,會輸出以下數值摘要:
--- 膽固醇數據描述統計結果 ---
算術平均數 (Mean) : 227.05 mg/dL
中位數 (Median) : 222.5 mg/dL
標準差 (SD) : 40.71657 mg/dL
變異數 (Variance) : 1657.839
全距 (Range) : 160 ~ 310 (全距大小 = 150 )
變異係數 (CV) : 17.93 %
-----------------------------同時,你的 figs/ 資料夾下會生成以下兩張精美的繪圖:
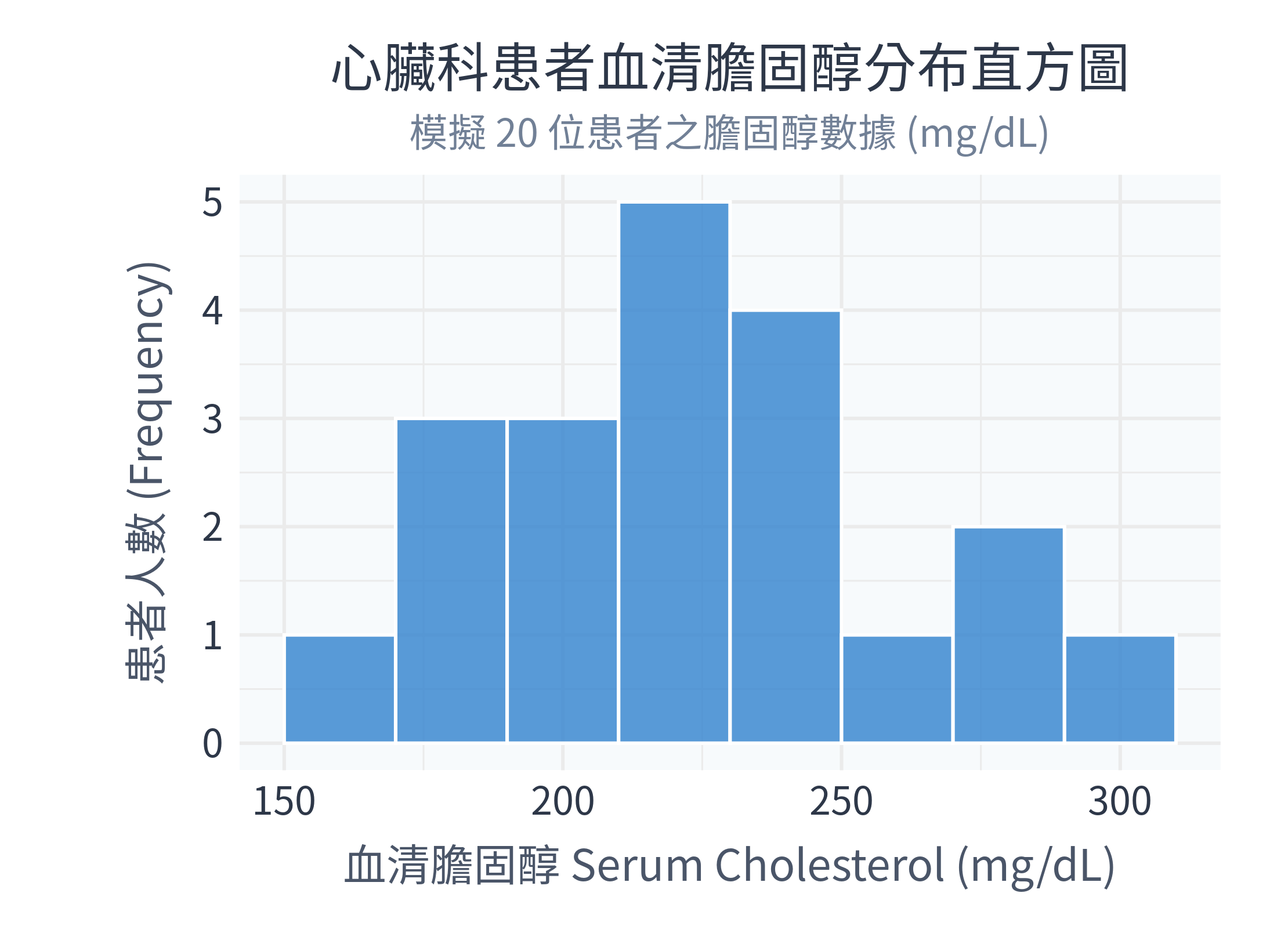
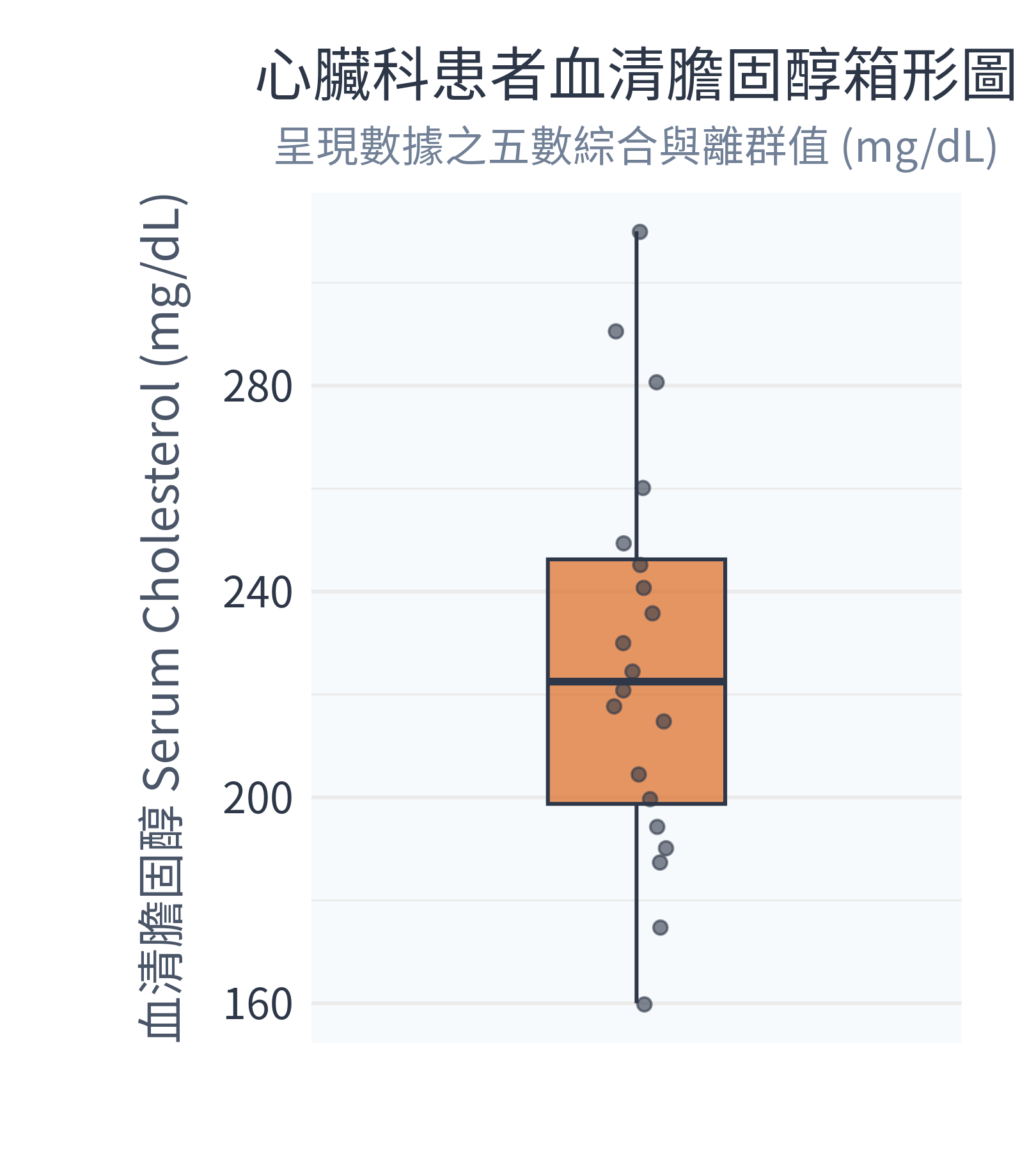
數據診斷分析:
- 分佈型態:我們的平均膽固醇是 227.05 mg/dL,中位數是 222.5 mg/dL。平均數略大於中位數,且從直方圖可以看出,分佈的右側(高數值端)稍微拉得比較長,這是一個輕微的右偏(正偏)分佈。
- 臨床離群值:在箱形圖中,雖然 310 mg/dL 這位患者(
ID_5)的數值偏高,但並未超出箱形圖上限(\(Q_3 + 1.5 \times IQR\)),因此在本範例中並未判定出嚴格的統計離群值。不過在臨床實務上,膽固醇高於 240 mg/dL 已屬於高膽固醇血症,需要特別加以衛教與控制!
2.6 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 位置量度 / 中心趨勢 | Measures of location / Central tendency | 描述一組數據核心集中位置的統計指標。 |
| 算術平均數 | Arithmetic mean | 所有數值之和除以數值個數所得的數值。 |
| 中位數 | Median | 數據從小到大排序後,位於最中間的數值。 |
| 眾數 | Mode | 數據集中出現次數或頻率最高的數值。 |
| 幾何平均數 | Geometric mean | 數據相乘後開 n 次方根所得的值,常用於對數級數成長的生物數據。 |
| 離散趨勢 | Measures of spread / Dispersion | 描述數據分布分散、波動或變異程度的指標。 |
| 全距 | Range | 數據集中最大值與最小值的差。 |
| 變異數 | Variance | 各數據與平均數離差平方的平均值(分母使用自由度 n-1)。 |
| 標準差 | Standard deviation | 變異數的平方根,表示數據的平均波動幅度。 |
| 變異係數 | Coefficient of variation (CV) | 標準差與平均數的比值,用百分比表示,便於比較不同單位之相對變異。 |
| 直方圖 | Histogram | 以矩形的寬度表示組距,高度表示頻數或頻率的統計分佈圖表。 |
| 箱形圖 (盒鬚圖) | Box plot (Box-and-whisker plot) | 呈現數據五數綜合(最小、Q1、中位、Q3、最大值)的統計圖表。 |
| 四分位距 | Interquartile range (IQR) | 第三四分位數與第一四分位數的差(Q3 - Q1),代表中間 50% 數據的寬度。 |
| 離群值 (極端值) | Outlier | 在統計上偏離其他觀測值非常遠的奇特數值。 |
| 右偏分布 (正偏分布) | Positively skewed / Right-skewed | 數據分布尾巴向右側(大數值端)拉長的偏態分布。 |
| 左偏分布 (負偏分布) | Negatively skewed / Left-skewed | 數據分布尾巴向左側(小數值端)拉長的偏態分布。 |