第十四章:假設檢定:人年數據與存活分析 (Hypothesis Testing: Person-Time Data and Survival Analysis)
14.1 導言:當時間遇上事件——什麼是「人年」?
同學們,歡迎來到第十四章!在上一章中,我們探討了流行病學研究設計的幾種經典指標(如相對危險度與勝算比)。當時,我們假設所有研究對象都被追蹤了「相同長度」的時間。但在真實的醫學世界中,這通常是個不切實際的幻想!
想像一下,你啟動了一個為期 5 年的「加護病房病患出院後存活追蹤研究」。
- 病患甲:入組後第 1 年就因為搬家而失去聯絡。
- 病患乙:入組後第 3 年不幸因病過世(發生事件)。
- 病患丙:非常配合,乖乖活著被你追蹤了整整 5 年直到研究結束。
如果我們只簡單計算「發病比例」,這三個人在分母的權重居然是一樣的!這顯然不公平,因為病患丙提供了 5 年的觀察時間,而病患甲只貢獻了 1 年。為了解決追蹤時間長短不一的問題,流行病學家引入了人時 (person-time)(最常用的是人年 (person-years))的概念。
14.1.1 發生密度 (Incidence Density, ID)
當我們將「時間」融入分母,計算出來的就稱為發生密度 (incidence density),或者稱為發生率 (incidence rate):
\[ID = \frac{D}{PT} = \frac{\text{追蹤期間內新發生的病例數 (D)}}{\text{所有研究對象貢獻的總追蹤人時 (PT)}}\]
例如,追蹤 100 位高血壓病患,有人追蹤 2 年,有人追蹤 5 年,加起來總共是 450 人年。期間共有 9 人中風。則該人群的中風發生密度為:
\[ID = \frac{9\text{ 人}}{450\text{ 人年}} = 0.02\text{ /人年} = 20\text{ /千人年}\]
也就是說,每 1000 人追蹤 1 年,預計會觀測到 20 起中風事件。人年數據讓我們能夠彈性處理追蹤時間不一致、受試者中途退出或加入的動態佇列數據。
14.2 單一樣本發生率之推論 (One-Sample Inference)
當我們想評估某個特殊佇列(例如:某化工廠員工的癌症發生率)是否顯著高於一般大眾的標準發生率 \(\lambda_0\) 時,我們會使用單一樣本推論。
由於罕見事件在大量觀察時間下的發生次數非常符合卜瓦松分布 (Poisson distribution)。我們可以將觀測到的事件數 \(D\) 視為卜瓦松隨機變數。我們想檢定:
\[H_0: \lambda = \lambda_0 \quad \text{vs.} \quad H_1: \lambda \ne \lambda_0\]
其中 \(\lambda\) 為該廠員工的真實發生率,而我們觀測到的總人年為 \(T\)。
14.2.1 假設檢定方法
在虛無假設 \(H_0\) 成立下,預期會發生的事件數(期望值)為:
\[E = \lambda_0 \times T\]
- 精確檢定 (Exact Test):當觀測事件數 \(D\) 較小(例如 \(D < 20\))時,直接利用卜瓦松機率公式計算雙尾 \(p\) 值。
- 常態近似法 (Normal Approximation):當事件數足夠大(例如 \(D \ge 20\))時,我們可以使用常態近似。檢定統計量為:
\[z = \frac{D - E}{\sqrt{E}}\]
在 \(H_0\) 下,該統計量近似服從標準常態分布 \(N(0, 1)\)。
14.3 兩獨立樣本發生率之比較 (Two-Sample Inference)
在臨床試驗或佇列研究中,我們更常需要比較「暴露組」與「非暴露組」(或治療組與對照組)的發生率是否不同。
設兩組的觀測事件數與總人年分別為:
- 第 1 組(暴露組):事件數 \(D_1\),總人年 \(T_1\),發生率 \(ID_1 = D_1 / T_1\)
- 第 2 組(對照組):事件數 \(D_2\),總人年 \(T_2\),發生率 \(ID_2 = D_2 / T_2\)
我們最關心的關聯性測量指標是發生密度比 (incidence density ratio, IDR),有時也直接稱為發生率比 (rate ratio):
\[IDR = \frac{ID_1}{ID_2} = \frac{D_1 / T_1}{D_2 / T_2}\]
14.3.1 假設檢定:常態近似法
我們檢定 \(H_0: \lambda_1 = \lambda_2\)(兩組真實發生率相等)。若事件總數 \(D_1 + D_2 \ge 20\),可使用常態近似檢定。
我們定義在虛無假設下,第 1 組事件數的期望值為:
\[E_1 = (D_1 + D_2) \times \frac{T_1}{T_1 + T_2}\]
檢定統計量 \(z\) 為:
\[z = \frac{D_1 - E_1}{\sqrt{Var(D_1)}} = \frac{D_1 - E_1}{\sqrt{(D_1 + D_2) \times \frac{T_1 T_2}{(T_1 + T_2)^2}}}\]
在 \(H_0\) 下,此統計量近似服從標準常態分布。
14.3.2 IDR 的信賴區間
由於 IDR 是個比值,其分布通常偏斜。我們常用對數轉換 (log transformation) 來使其接近常態分布。
\(\ln(IDR)\) 的標準誤 (Standard Error, SE) 估計為:
\[SE(\ln(IDR)) \approx \sqrt{\frac{1}{D_1} + \frac{1}{D_2}}\]
因此,\(\ln(IDR)\) 的 \(95\%\) 信賴區間為:
\[\ln(IDR) \pm 1.96 \times \sqrt{\frac{1}{D_1} + \frac{1}{D_2}}\]
將兩端點取指數 (\(e^x\)),即可得到 \(IDR\) 的真實 \(95\%\) 信賴區間。若該區間不包含 1,代表兩組發生率有顯著差異。
14.4 存活分析基礎:設限與 Kaplan-Meier 估計
當我們的研究重點不只是「有沒有發生事件」,而是「什麼時候發生事件」(即事件發生前的生存時間 (survival time))時,我們就需要使用存活分析 (survival analysis)。
14.4.1 什麼是設限 (Censoring)?
在存活分析中,最獨特的特徵就是設限 (censoring)(通常指右設限 (right censoring))。當研究結束時,某位受試者仍活著,或者他在研究中途因為非研究原因退出(失聯、搬家、意外死亡),我們只知道他的生存時間「至少大於某個時間點」,但不知道確切的死亡時間。這種數據就稱為設限數據。
我們絕不能拋棄設限數據!因為他們活過了這段時間,提供了寶貴的存活資訊。
14.4.2 Kaplan-Meier 乘積極限估計法 (Product-Limit Estimator)
為了在計算累積存活率時正確納入設限資訊,Kaplan 與 Meier 於 1958 年提出了著名的 Kaplan-Meier 估計法。
假設我們將觀測到的事件發生時間從小到大排序為:\(t_1 < t_2 < \dots < t_k\)。 在每個時間點 \(t_i\):
- \(n_i\):在 \(t_i\) 剛開始時,仍處於風險中(即存活且未設限)的病患人數 (number at risk)。
- \(d_i\):在 \(t_i\) 時刻發生事件(如死亡)的人數。
那麼,在 \(t_i\) 時刻的條件存活機率為 \(1 - \frac{d_i}{n_i}\)。 將各時間點的條件機率相乘,即可得到截至時間 \(t\) 的累積存活率 (cumulative survival rate):
\[\hat{S}(t) = \prod_{t_i \le t} \left(1 - \frac{d_i}{n_i}\right)\]
當沒有人死亡或設限時,累積存活率保持不變;當有人死亡時,存活曲線會呈現梯形「階梯式」往下降。設限點則通常在曲線上以「+」號標記,此時風險人數 \(n_i\) 會在下一個時間點減少,但累積存活率本身不變。
14.5 存活曲線的比較:對數秩檢定 (Log-rank Test)
當我們繪製出兩組(如新藥組 vs. 對照組)的 Kaplan-Meier 存活曲線後,肉眼看起來有差距,但統計上真的顯著嗎?我們不能用 \(t\) 檢定(因為有設限數據,且生存時間通常不呈常態分布)。
最常用的無母體檢定方法是對數秩檢定 (log-rank test)。
14.5.1 對數秩檢定的基本原理
我們將兩組的數據合併,並在每一個觀測到事件的時間點 \(t_i\) 建立一個 2x2 列聯表:
| 組別 | 發生事件數 | 未發生事件 (存活) | 風險人數 |
|---|---|---|---|
| 第 1 組 | \(d_{1i}\) | \(n_{1i} - d_{1i}\) | \(n_{1i}\) |
| 第 2 組 | \(d_{2i}\) | \(n_{2i} - d_{2i}\) | \(n_{2i}\) |
| 總計 | \(d_i\) | \(n_i - d_i\) | \(n_i\) |
在虛無假設 \(H_0\)(兩組存活曲線無差異)成立下,第 1 組在時間點 \(t_i\) 的預期死亡數(期望值)為:
\[E_{1i} = d_i \times \frac{n_{1i}}{n_i}\]
我們將所有事件時間點的觀測值與期望值分別累加:
\[O_1 = \sum d_{1i}, \quad E_1 = \sum E_{1i}\]
對數秩檢定統計量 \(X^2\) 為:
\[X^2 = \frac{(O_1 - E_1)^2}{Var(O_1 - E_1)}\]
在虛無假設下,此統計量近似服從自由度為 1 的卡方分布 (\(\chi^2_1\))。若 \(p < 0.05\),則代表兩組的存活曲線有顯著差異。
14.6 比例風險模式:Cox 迴歸 (Cox Proportional Hazards Model)
對數秩檢定雖然強大,但它和單因子變異數分析 (One-way ANOVA) 一樣,無法同時控制多個混淆因子(如年齡、共病症、病情嚴重度)。
為了解決多變量存活分析的問題,戴維·考克斯 (David Cox) 於 1972 年提出了 Cox 比例風險模式 (Cox Proportional Hazards Regression Model)。
14.6.1 模式數學公式
Cox 迴歸屬於半母體模式 (semi-parametric model),它將某個時間點 \(t\) 的風險函數 (hazard function) \(h(t)\) 表示為:
\[h(t, X) = h_0(t) \exp(\beta_1 X_1 + \beta_2 X_2 + \dots + \beta_k X_k)\]
- \(h_0(t)\):基準風險函數 (baseline hazard),代表當所有自變量 \(X_i = 0\) 時的風險。它隨時間變化的趨勢不需要預設任何分布(這就是半母體的由來)。
- \(\exp(\beta_i)\):風險比 (hazard ratio, HR)。
14.6.2 風險比 (HR) 的解讀
風險比 (HR) 代表當自變量 \(X_i\) 每增加一個單位時,事件發生風險的倍數:
- \(HR = 1\):該變數與風險無關。
- \(HR > 1\):該變數是危險因子(事件發生風險增加,存活率下降)。
- \(HR < 1\):該變數是保護因子(如新藥治療使死亡風險降低,存活率上升)。
⚠️ 比例風險假設 (Proportional Hazards Assumption): Cox 模式最重要的前提是:不同組別之間的風險比 (HR) 在整個追蹤期間必須保持恆定。也就是說,兩組風險曲線不能交叉,否則會違反比例風險假設,需要使用進一步的時變協變量 (time-varying covariates) 修正。
14.7 實戰演練:加護病房病患存活分析
現在,讓我們啟動 RStudio,用真實的臨床情境來實作人年數據與存活曲線的繪製!
14.7.1 臨床情境說明
我們收集了 30 位重症加護病房 (ICU) 病患的臨床追蹤數據。這群人被分為兩組:
- 新藥治療組 (Treatment Group) (\(n=15\))
- 常規對照組 (Control Group) (\(n=15\))
我們追蹤他們自入 ICU 起 60 天內的存活狀況。數據中包含:
Time:追蹤時間 (天)。Status:存活狀態。1代表觀測到死亡事件;0代表設限 (censored,如存活出院、轉院或追蹤期滿仍存活)。Group:病患分組。
我們將在 RStudio 中:
- 建立存活物件。
- 進行 Kaplan-Meier 生存曲線估計。
- 執行 Log-rank 檢定比較兩組存活率。
- 建立 Cox 比例風險模式,計算風險比 (HR)。
- 使用
ggplot2繪製高水準的生存曲線階梯圖,並標註設限點與 Log-rank \(p\) 值。
14.7.2 RStudio 操作步驟
- 開啟 RStudio,在右上角點選 File -> New File -> R Script。
- 安裝與載入套件:存活分析需要使用 R 內建的
survival套件。 - 將下方的 R 程式碼複製並貼入編輯器中。
- 選取全部程式碼,按 Run 執行。
14.7.3 R 程式碼實作
# 1. 載入必備套件
library(survival)
library(ggplot2)
# 2. 建立 ICU 病患存活模擬數據
set.seed(77)
# 新藥治療組 (n=15):生存時間較長,設限比例高
time_treat <- c(12, 18, 25, 30, 30, 35, 40, 45, 50, 55, 60, 60, 60, 60, 60)
status_treat <- c(1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0) # 0 = 設限, 1 = 死亡
# 常規對照組 (n=15):生存時間較短,死亡比例高
time_ctrl <- c(5, 8, 12, 15, 18, 20, 24, 30, 35, 40, 45, 50, 50, 50, 50)
status_ctrl <- c(1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0)
# 合併成資料框
surv_df <- data.frame(
Time = c(time_treat, time_ctrl),
Status = c(status_treat, status_ctrl),
Group = factor(c(rep("新藥治療組 (Treatment)", 15), rep("常規對照組 (Control)", 15)))
)
# 3. 建立存活物件並進行 Kaplan-Meier 估計
# Surv(Time, Status) 會將時間與事件狀態結合成存活分析專用格式
fit <- survfit(Surv(Time, Status) ~ Group, data = surv_df)
# 4. 執行 Log-rank 檢定比較兩組存活曲線
logrank_res <- survdiff(Surv(Time, Status) ~ Group, data = surv_df)
p_val <- 1 - pchisq(logrank_res$chisq, df = length(logrank_res$n) - 1)
# 5. 建立 Cox 比例風險模式
cox_model <- coxph(Surv(Time, Status) ~ Group, data = surv_df)
cox_summary <- summary(cox_model)
# 6. 輸出控制台分析結果
cat("=========================================\n")
cat(" 實作一:Log-rank 檢定結果\n")
cat("=========================================\n")
print(logrank_res)
cat("Log-rank Test p-value:", round(p_val, 5), "\n")
cat("\n=========================================\n")
cat(" 實作二:Cox 比例風險模式結果\n")
cat("=========================================\n")
print(cox_summary)
# =======================================================
# 7. 整理存活曲線數據並以 ggplot2 繪圖
# =======================================================
# 提取生存估計摘要
fit_summary <- summary(fit, censored = TRUE)
fit_df <- data.frame(
Time = fit_summary$time,
Survival = fit_summary$surv,
Censored = fit_summary$n.censor,
Group = fit_summary$strata
)
# 清理分組名稱
fit_df$Group <- gsub("Group=", "", fit_df$Group)
# 加入時間 0,累積存活率 100% 的起點,讓曲線從最左側開始
t_start <- data.frame(
Time = c(0, 0),
Survival = c(1, 1),
Censored = c(0, 0),
Group = c("常規對照組 (Control)", "新藥治療組 (Treatment)")
)
fit_plot_df <- rbind(t_start, fit_df)
# 篩選出有設限點的數據列,用於在地圖上點綴 + 號
censor_points <- subset(fit_plot_df, Censored > 0)
# 繪製生存階梯圖
p_surv <- ggplot(fit_plot_df, aes(x = Time, y = Survival, color = Group)) +
# geom_step 專門用於繪製存活曲線的階梯狀走勢
geom_step(linewidth = 1.2) +
# 繪製設限標記 (shape = 3 代表十字 "+" 號)
geom_point(data = censor_points, aes(x = Time, y = Survival), shape = 3, size = 3, stroke = 1.2) +
scale_color_manual(values = c("常規對照組 (Control)" = "#e53e3e", "新藥治療組 (Treatment)" = "#3182ce")) +
scale_y_continuous(limits = c(0, 1.05), labels = scales::percent) +
# 標註 Log-rank 檢定之 p 值
annotate("text", x = 15, y = 0.25, label = paste("Log-rank Test\np-value =", round(p_val, 4)),
size = 6.2, color = "#2d3748", family = "Noto Sans CJK TC", fontface = "bold") +
labs(
title = "重症加護病房病患 Kaplan-Meier 生存曲線",
subtitle = "對比新藥治療組與常規對照組之存活率與設限點 (Censored)",
x = "觀察時間 Time (days)",
y = "累積存活率 Cumulative Survival Rate",
color = "病患分組"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows系統請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
legend.title = element_text(size = 16, color = "#4a5568"),
legend.position = "bottom",
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 儲存圖檔
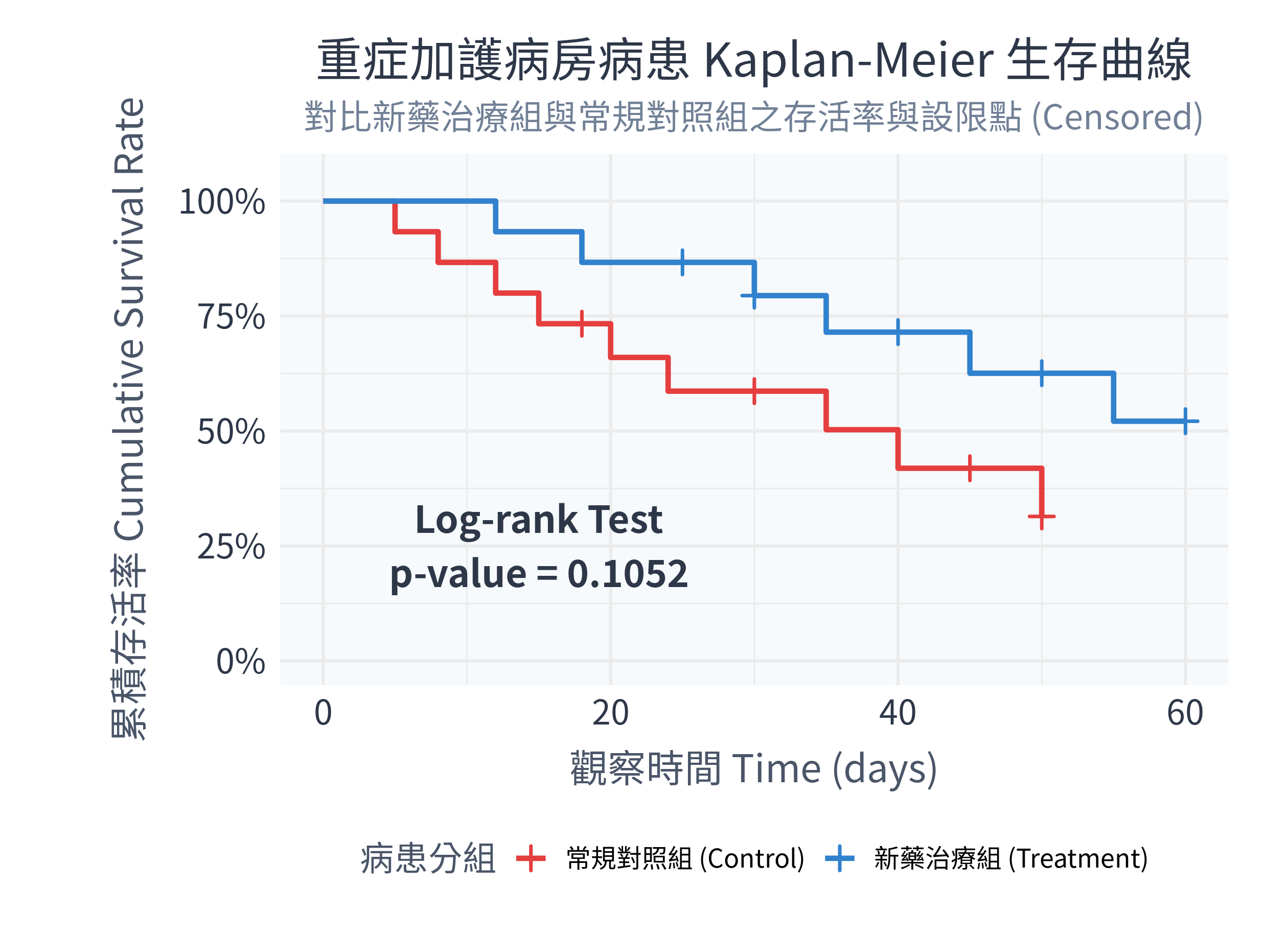
ggsave("figs/survival_curves.png", plot = p_surv, width = 8.4, height = 6.1, dpi = 300)14.7.4 執行結果與圖表解讀
當你在 RStudio 中執行上述程式碼後,控制台會顯示以下關鍵數據:
Log-rank 檢定輸出:
N Observed Expected (O-E)^2/E (O-E)^2/V Group=常規對照組 (Control) 15 10 6.56 1.80 3.05 Group=新藥治療組 (Treatment) 15 6 9.44 1.25 3.05- 這裡算出的卡方統計量為 3.05,自由度 (df) = 1,對應的 \(p\)-value = 0.10518。
- 雖然新藥治療組的死亡事件數(6人)少於常規對照組(10人),但因為小樣本限制,Log-rank 檢定的結果在 \(\alpha = 0.05\) 下未達到統計學上的顯著差異。我們暫時無法斷定新藥能顯著提升 ICU 病患的生存率。
Cox 比例風險模式輸出:
模式結果中會指出新藥組相較於對照組的風險比 (Hazard Ratio, HR):
HR = 0.447(95% CI: 0.162 到 1.233)。這代表接受新藥治療的患者,其死亡風險在任何給定時間點大約是常規治療組的 44.7%。雖然這顯示了強烈的保護趨勢,但其 95% 信賴區間跨越了 1.0,且 Cox 迴歸的 \(p\) 值為 0.119,同樣不具統計顯著性。
同時,figs/ 資料夾下會生成以下精美的存活曲線圖:
數據診斷分析與繪圖技術說明:
- 設限符號 (Censored):紅線與藍線上的小「+」號就是設限點。你可以看到,新藥治療組在 60 天結束時,有大量的病患仍然存活(藍線末端沒有再往下降,而是以多個設限點結束),這正體現了存活分析處理不完全追蹤數據的能力。
- 階梯圖的繪製 (geom_step):在 ggplot2 中,我們沒有使用一般的
geom_line(),而是使用geom_step()。因為存活率只在「發生死亡事件的時間點」才會瞬間下降,在事件之間的時間內,存活率是保持水平不變的。使用階梯圖能精準還原這種階梯變化的臨床事實。 - 字型與排版:為了保證中文標題在 Linux headless 伺服器上能順利渲染,我們在
theme_minimal中設置了base_family = "Noto Sans CJK TC"。同學們如果在 Windows 系統上執行,建議將其改為"Microsoft JhengHei"(微軟正黑體);在 macOS 系統上則改為"Heiti TC"(黑體-繁),這樣字型才會完美呈現喔!
14.8 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 人時 / 人年 | Person-time / Person-years | 結合研究人數與各自追蹤時間長短的複合分母指標,常用於變動追蹤時間之研究。 |
| 發生密度 | Incidence density (ID) | 每單位人時內新發病例的發生速率,即新發病例數除以總人時。 |
| 發生率比 (發生密度比) | Rate ratio / Incidence density ratio (IDR) | 兩組人群發生密度之比值,用以評估暴露或治療對發病率的影響強弱。 |
| 存活分析 | Survival analysis | 用於分析從研究起點到某一事件(如死亡、發病、復發)發生所經歷之時間的統計方法。 |
| 生存時間 | Survival time | 指研究對象從起點狀態到觀測到事件發生或設限所經歷的時間跨度。 |
| 設限 (右設限) | Censoring (Right censoring) | 研究結束時事件仍未發生,或受試者因中途失聯、退出而無法得知其確切事件時間的狀況。 |
| 乘積極限估計法 | Product-limit estimator | 即 Kaplan-Meier 估計法,用於計算含有設限數據之累積存活率的非母體方法。 |
| 對數秩檢定 | Log-rank test | 一種非母體檢定,用於比較兩組或多組存活曲線是否有統計學上的顯著差異。 |
| Cox 比例風險模式 | Cox proportional hazards model | 一種用於存活分析的多變量半母體迴歸模式,可評估多個自變數對風險函數的影響。 |
| 風險比 | Hazard ratio (HR) | 暴露組相較於非暴露組在給定時間點發生事件的相對風險比值。 |
| 比例風險假設 | Proportional hazards assumption | Cox 迴歸的核心前提,要求不同組別之間的風險比在整個隨訪期間保持恆定不變。 |