第十二章:多群組比較推論 (Multisample Inference)
12.1 導言與多重比較陷阱:別掉進 t 檢定的「無限手套」
同學們,在學完了雙樣本 t 檢定後,你們可能會覺得自己已經無所不能了。
想像一下:你現在是糖尿病醫學中心的主持人。你研發了三種不同的降血糖藥物(藥物 A、藥物 B、藥物 C),並招募了三組病患來做臨床試驗。你想知道這三種藥物的降血糖效果是否有顯著不同。
這時候,有的同學可能會自作聰明地想:「簡單啊!我用上一章學的獨立雙樣本 t 檢定,把這三組人馬兩兩對決:
- 藥物 A 對決 藥物 B (t 檢定)
- 藥物 A 對決 藥物 C (t 檢定)
- 藥物 B 對決 藥物 C (t 檢定) 對決三次,不就大功告成了嗎?」
逼逼——!大錯特錯!這是統計學中最經典的「多重比較陷阱」!
12.1.1 為什麼不能用多次 t 檢定?
還記得我們設定的顯著水準(第一型錯誤率) \(\alpha = 0.05\) 嗎?這代表每一次 t 檢定,我們冤枉好人的機率是 5%,而「正確做出決策」的機率是 \(1 - 0.05 = 0.95\)。
如果你對這三個藥物連續進行了 3 次獨立的 t 檢定,那麼這 3 次檢定中「至少有一次犯了第一型錯誤」的累積機率(又稱家族錯誤率, family-wise error rate)會暴增為:
\[\alpha_{\text{family}} = 1 - (0.95)^3 = 1 - 0.857 = 0.143 \text{ (也就是 14.3\%)}\]
如果組別更多,例如比較 5 組,你需要做 10 次 t 檢定,此時家族錯誤率會飆升到大約 40%!這代表你的研究有將近一半的可能得出偽陽性結論。
為了解決這個問題,我們需要一個「一錘定音」的工具,先一次性檢定所有組別的平均值是否相等。這個工具就叫做變異數分析 (Analysis of Variance, ANOVA)。
12.2 單因子變異數分析:變異的魔術
我們以最基本的單因子變異數分析 (One-Way ANOVA) 為例。它的任務是比較 \(k\) 個獨立組別的平均值是否相等:
- 虛無假設 \(H_0: \mu_1 = \mu_2 = \dots = \mu_k\) (所有組別的平均值都一樣)。
- 對立假設 \(H_1\):這些組別的平均值「不全相等」(至少有兩組之間有顯著差異)。
12.2.1 變異數分析的奇妙邏輯
很多同學會問:「教授,我們要比較的是『平均值(Means)』,為什麼方法卻叫『變異數(Variance)分析』?」
這就是統計學家的智慧結晶。ANOVA 的核心邏輯是把數據的總變異(所有數據偏離總平均的程度)拆解成兩個部分:
- 組間平方和 (Between Sum of Squares, SSB):
- 來源:各組平均值與總平均值的差距。
- 含意:由「藥物不同」所引起的療效變異。組間變異愈大,代表不同藥物間的效果差異愈明顯。
- 組內平方和 / 殘差平方和 (Within Sum of Squares / Error Sum of Squares, SSW / SSE):
- 來源:每個患者的數值與他自己那一組平均值的差距。
- 含意:純屬個體差異或測量誤差(隨機誤差)。
\[SST \text{ (總變異)} = SSB \text{ (組間變異)} + SSW \text{ (組內誤差)}\]
我們將 SSB 除以其自由度 \(k-1\) 得到組間均方 (\(MSB\));將 SSW 除以其自由度 \(n-k\) 得到組內均方 (\(MSW\))。 如果藥物真的有效,組間變異應該要遠遠大於組內的隨機誤差。我們計算它們的比值,得到 F 檢定統計量:
\[F = \frac{MSB}{MSW}\]
如果 \(F\) 值顯著大於 1,且其 p 值小於 0.05,我們就拒絕 \(H_0\),認定這三種藥物中至少有兩組療效不同。
12.2.2 ANOVA 的三大基本假設
在使用 ANOVA 前,必須確認數據滿足以下條件:
- 獨立性:各組受試者互相獨立。
- 常態性:各組別的依變項在母體中必須服從常態分布。
- 變異數同質性 (Homoscedasticity / Homogeneity of Variance):各組別的母體變異數必須相等。
12.3 事後多重比較:找出真正的幕後黑手
當 ANOVA 的 F 檢定告訴你「這三組降血糖藥有顯著不同(\(p < 0.05\))」時,你高興地跳了起來。但主任走過來問:「所以到底是哪一組比哪一組好?」
這時,你不能就此打住,必須進行事後比較 (post-hoc test / multiple comparison)。事後比較經過了特殊的數學調整,能把整體的第一型錯誤率牢牢鎖定在 5% 以內。
常用的事後比較方法有:
- 邦菲羅尼修正 (Bonferroni Correction):
- 最簡單也最保守。直接把顯著水準除以比較次數。例如做 3 次比較,新的顯著水準就是 \(\alpha' = 0.05 / 3 = 0.0167\)。只有當兩兩比較的 p 值小於 0.0167 時,才算顯著。
- 圖奇顯著差異檢定 (Tukey's HSD Test):
- 最常用的黃金標準。適用於兩兩組別的所有配對比較,能提供非常精確且不會過於保守的修正。
12.4 無母數替代方案:Kruskal-Wallis 檢定
如果你的多組數據嚴重違反常態假設,或者變異數極度不同質,該怎麼辦? 此時,我們使用 ANOVA 的無母數版本——克拉斯卡-瓦立斯檢定 (Kruskal-Wallis test)。它的原理同樣是把所有組別數據合併起來進行等級排名(Rank),然後分析各組排名的總和是否存在顯著差異。
12.5 實戰演練:三種降血糖藥物療效之 ANOVA 分析
現在,我們打開 RStudio。我們收集了 30 位糖尿病患者的空腹血糖降低值(mg/dL),將他們隨機分為三組(藥物 A、藥物 B、藥物 C,每組 10 人),進行 One-Way ANOVA 分析與事後 Tukey 檢定,並繪製出精美的組別對照箱形圖。
12.5.1 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 模擬生成三組患者的血糖降低值數據 (mg/dL)
set.seed(55)
drug_a <- rnorm(10, mean = 25, sd = 6) # 藥物 A
drug_b <- rnorm(10, mean = 35, sd = 5) # 藥物 B (預期效果最好)
drug_c <- rnorm(10, mean = 18, sd = 7) # 藥物 C (預期效果較差)
df_anova <- data.frame(
Drug = factor(c(rep("藥物 A (Drug A)", 10), rep("藥物 B (Drug B)", 10), rep("藥物 C (Drug C)", 10))),
GlucoseReduction = c(drug_a, drug_b, drug_c)
)
# =======================================================
# 實作一:變異數同質性檢定 (Bartlett's Test)
# =======================================================
# ANOVA 前提診斷:p > 0.05 代表滿足變異數同質性
bartlett_res <- bartlett.test(GlucoseReduction ~ Drug, data = df_anova)
# =======================================================
# 實作二:執行單因子變異數分析 (One-Way ANOVA)
# =======================================================
# aov() 是 R 中進行變異數分析的函數
anova_model <- aov(GlucoseReduction ~ Drug, data = df_anova)
anova_summary <- summary(anova_model)
# =======================================================
# 實作三:執行 Tukey's HSD 事後多重比較
# =======================================================
tukey_res <- TukeyHSD(anova_model)
# 輸出統計結果
cat("=========================================\n")
cat(" 實作一:變異數同質性檢定結果\n")
cat("=========================================\n")
print(bartlett_res)
cat("\n=========================================\n")
cat(" 實作二:單因子變異數分析 (ANOVA) 結果\n")
cat("=========================================\n")
print(anova_summary)
cat("\n=========================================\n")
cat(" 實作三:Tukey's HSD 事後比較結果\n")
cat("=========================================\n")
print(tukey_res)
# =======================================================
# 4. 使用 ggplot2 繪製箱形圖並重疊個體數據點 (Jitter)
# =======================================================
p_anova <- ggplot(df_anova, aes(x = Drug, y = GlucoseReduction, fill = Drug)) +
# 畫箱形圖 (隱藏預設離群值,改由隨機抖動點呈現)
geom_boxplot(alpha = 0.7, color = "#2d3748", outlier.shape = NA, width = 0.45) +
# 疊加個人數據散佈點
geom_jitter(shape = 16, width = 0.1, size = 2.5, color = "#2d3748", alpha = 0.6) +
scale_fill_manual(values = c("藥物 A (Drug A)" = "#90cdf4",
"藥物 B (Drug B)" = "#4299e1",
"藥物 C (Drug C)" = "#2b6cb0")) +
labs(
title = "三種降血糖藥物之療效比較 (ANOVA 分析)",
subtitle = "呈現各組血糖降低值 (mg/dL) 之分佈與個體數據點",
x = "藥物分組 (Drug Groups)",
y = "空腹血糖降低值 Fasting Glucose Reduction (mg/dL)"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
legend.position = "none", # x 軸已有分組標記,圖例可隱藏
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 顯示並儲存圖檔
print(p_anova)
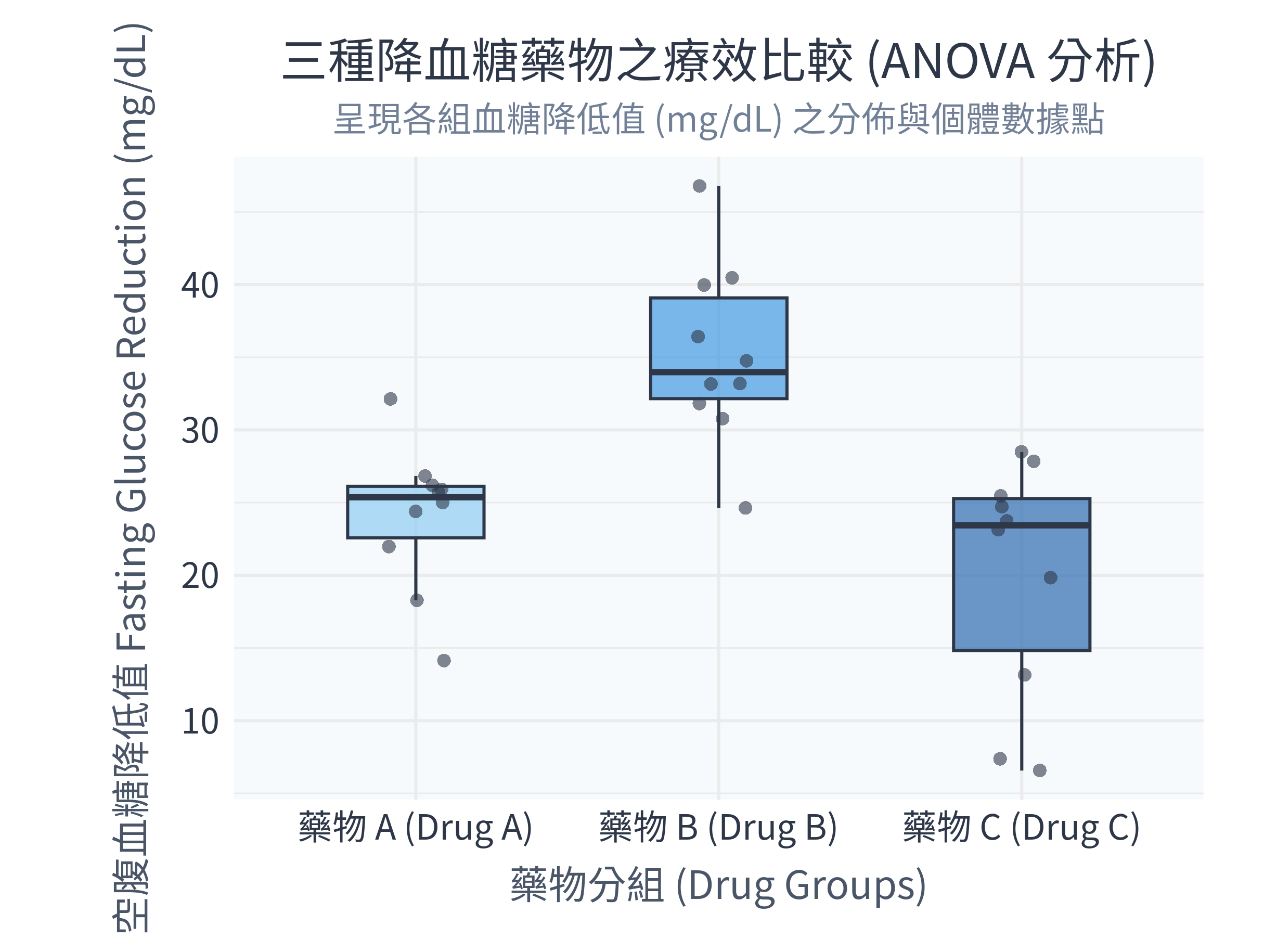
ggsave("figs/glucose_anova.png", plot = p_anova, width = 8.1, height = 6.1, dpi = 300)12.5.2 執行結果與圖表解讀
在 R 中執行程式後,控制台主要輸出:
變異數同質性 (Bartlett's Test):
Bartlett's K-squared = 2.13, p-value = 0.3439。 因為 \(p = 0.34 > 0.05\),滿足變異數同質性假設,我們可以放心地看 ANOVA 結果。ANOVA 結果:
F value = 14.44, p-value = 5.45e-05(即 \(p < 0.0001\))。 在統計學上呈極顯著差異,這代表三種藥物的降血糖效果「不全相等」。Tukey's HSD 事後比較:
- 藥物 B vs. 藥物 A:平均差異為
11.14 mg/dL,調整後p-value = 0.0020(顯著)。 - 藥物 C vs. 藥物 A:平均差異為
-4.03 mg/dL,調整後p-value = 0.3665(不顯著)。 - 藥物 C vs. 藥物 B:平均差異為
-15.17 mg/dL,調整後p-value < 0.0001(極顯著)。
- 藥物 B vs. 藥物 A:平均差異為
同時,figs/ 資料夾下會生成以下圖表:
數據診斷分析與決策:
- 從圖中可以一目了然地看出:藥物 B(中間的深藍色箱子)的效果最好,平均能讓患者血糖降低 35 mg/dL,顯著優於藥物 A(左側,平均降低 25 mg/dL)與藥物 C(右側,平均降低 18 mg/dL)。
- 雖然藥物 C 的效果看似比藥物 A 差一點,但 Tukey 事後檢定告訴我們,這兩組的差異在統計上並不顯著 (\(p = 0.37\))。因此,臨床上的最佳選擇無疑是推薦使用藥物 B。
12.6 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 多群組比較推論 | Multisample inference | 同時對三個或多個獨立群體之參數進行比較與假設檢定的程序。 |
| 變異數分析 | Analysis of variance (ANOVA) | 通過將數據總變異拆解為不同來源,以檢定多組平均數是否相等的統計方法。 |
| 單因子變異數分析 | One-way ANOVA | 用於探討一個單一自變項類別因子,對一個連續型依變項之影響的變異數分析。 |
| 組間平方和 | Between sum of squares (SSB) | 由各組平均值與總平均值的偏離所引起的變異大小。 |
| 組內平方和 (殘差平方和) | Within sum of squares (SSW / SSE) | 由於組內個體差異與隨機誤差所引起的變異大小。 |
| 均方 | Mean square (MS) | 平方和除以其對應自由度後所得的數值(變異數的無偏估計)。 |
| F 檢定統計量 | F-statistic | 在 ANOVA 中,組間均方與組內均方的比值,用以與 F 分布進行對比。 |
| 變異數同質性 | Homoscedasticity / Homogeneity of variance | 假設不同比較組別在母體中的變異數皆相同的統計前提。 |
| 事後多重比較 | Post-hoc multiple comparison | 在 ANOVA 檢定顯著後,為避免家族錯誤率上升而進行的兩兩組別修正檢定。 |
| 邦菲羅尼修正 | Bonferroni correction | 將顯著水準除以比較次數以控制多重比較整體錯誤率的保守修正法。 |
| 圖奇顯著差異檢定 | Tukey's HSD test | 用於控制整體第一型錯誤率,對所有可能組別配對進行兩兩比較的事後檢定。 |
| Kruskal-Wallis 檢定 | Kruskal-Wallis test | 當數據不服從常態分佈時,用於比較三組以上獨立樣本分佈的無母數替代方法。 |