第十三章:流行病學研究設計與分析技術 (Design and Analysis Techniques for Epidemiologic Studies)
13.1 導言與流行病學研究設計:尋找疾病的「幕後元兇」
同學們,在前面幾章,我們學習了許多假設檢定的方法。今天,我們要將這些統計武器,帶入公共衛生與臨床醫學的核心戰場——流行病學 (epidemiology)。
流行病學的任務是:「研究人群中疾病的分布與決定因素,並找出引發疾病的風險因子。」 為了達成這個目的,流行病學家設計了幾種經典的研究模型,它們在統計分析上各有不同的要求:
- 前瞻性佇列研究 (Prospective Cohort Study):
- 設計:追蹤一群現在健康、但「暴露狀態不同」(例如一組吸菸、一組不吸菸)的人群,追蹤他們未來數年後,是否會發展出某種疾病(如肺癌)。
- 特徵:耗時長、成本高,但能直接計算疾病的「發生率」,並確立時間上的因果順序(先暴露、後發病)。
- 回顧性病例對照研究 (Retrospective Case-Control Study):
- 設計:先找出已經患有某病的人(病例組, Cases)以及沒患病的人(對照組, Controls),再回溯調查他們過去的暴露歷史(例如過去有沒有吸菸)。
- 特徵:省時省力,非常適合用於研究罕見疾病,但容易產生回憶偏誤(recall bias),且無法直接計算發病率。
- 橫斷面研究 (Cross-Sectional Study):
- 設計:在同一個時間點,測量一群人的暴露狀態與疾病狀態(例如問卷普查)。
- 特徵:快速,但無法確立「先因後果」的時間關係。
13.2 關聯性測量指標:相對危險度與勝算比
在流行病學中,我們使用以下三個經典的比例指標,來量化暴露與疾病之間的關係強弱:
13.2.1 相對危險度 (Relative Risk, RR)
相對危險度是佇列研究的專屬指標。它是暴露組的發病率與非暴露組的發病率之比值:
\[RR = \frac{\text{暴露組發病率}}{\text{非暴露組發病率}} = \frac{a / (a+b)}{c / (c+d)}\]
- \(RR = 1\):暴露與發病無關。
- \(RR > 1\):暴露是危險因子(如吸菸使肺癌風險增加)。
- \(RR < 1\):暴露是保護因子(如運動使心臟病風險降低)。
13.2.2 勝算比 (Odds Ratio, OR)
在病例對照研究中,因為我們是一開始就人為決定了病例組與對照組的人數,這打破了母體中真實的發病率,因此我們不能計算發病率,也就無法計算相對危險度 (RR)。
此時,我們必須改算勝算比 (OR),即「病例組的暴露勝算」與「對照組的暴露勝算」之比值:
\[OR = \frac{a \times d}{b \times c}\]
💡 罕見疾病假設 (Rare Disease Assumption): 雖然 OR 與 RR 的概念不同,但在醫學研究中有一個非常神奇的橋樑:當我們研究的疾病非常罕見時(盛行率小於 5%),勝算比 (OR) 將會非常接近相對危險度 (RR)。 這代表我們可以用病例對照研究的 OR 值,來近似估算佇列研究的 RR 風險!
13.2.3 可歸因危險度 (Attributable Risk, AR)
可歸因危險度(又稱風險差, Risk Difference)是暴露組與非暴露組發病率的差值,代表「如果我們消除了暴露因子,暴露組中能減少多少比例的發病率」:
\[AR = \frac{a}{a+b} - \frac{c}{c+d}\]
13.3 混淆偏誤與分層分析:揭穿第三者的謊言
在流行病學分析中,最可怕的敵人叫做混淆偏誤 (confounding bias)。
想像一下:你調查發現「常喝咖啡的人(暴露),得到胰臟癌的機率顯著增高(疾病)」。你興奮地宣布咖啡是胰臟癌的危險因子。 但這時有學者指出:「常喝咖啡的人通常也比較常吸菸,而吸菸早已被證實會導致胰臟癌!」
在這個例子中,吸菸就是一個混淆變項 / 混淆因子 (confounding variable / confounder)。它同時與暴露(喝咖啡)及結果(胰臟癌)高度相關,從中作梗,讓我們誤以為咖啡會致癌。
為了消滅混淆因子的干擾,我們常用分層分析 (stratified analysis)——把數據按照混淆因子分成不同的子層(層, strata)。例如:
- 層 1:只分析「吸菸者」中,喝咖啡與胰臟癌的關係。
- 層 2:只分析「非吸菸者」中,喝咖啡與胰臟癌的關係。
13.3.1 曼特爾-海恩澤爾方法 (Mantel-Haenszel Method)
當我們分層後,我們會得到多個子層的 2x2 列聯表。此時,我們使用 Mantel-Haenszel 方法將這些子層的勝算比合併,計算出一個排除混淆干擾後的合併勝算比 (\(OR_{MH}\)):
\[OR_{MH} = \frac{\sum \frac{a_i d_i}{n_i}}{\sum \frac{b_i c_i}{n_i}}\]
並進行 Mantel-Haenszel 關聯性檢定,求得合併後的 p 值。
13.4 實戰演練:吸菸與冠心病關係之分層分析
現在,我們打開 RStudio。我們設計了一項病例對照研究,探討吸菸 (Smoking) 與冠心病 (CHD) 的關係。 然而,我們懷疑「年齡(AgeGroup,年輕組 <50歲 vs. 年長組 >=50歲)」是一個混淆因子,因為年紀大的人發病率高且吸菸習慣不同。我們將數據依照年齡進行分層,並在 R 中計算各別分層的 OR、合併的 Mantel-Haenszel OR,並繪製出專業的森林圖 (Forest Plot)。
13.4.1 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 建立分層的 2x2 列聯表 (3D Array)
# 數據結構:[吸菸狀態, 疾病狀態, 年齡分層]
# 第一層:年輕組 (<50) - 病例組: 10吸菸/10不吸菸; 對照組: 15吸菸/35不吸菸
# 第二層:年長組 (>=50) - 病例組: 25吸菸/15不吸菸; 對照組: 10吸菸/15不吸菸
tab_strata <- array(
c(10, 15, 10, 35, # 年輕組數據
25, 10, 15, 15), # 年長組數據
dim = c(2, 2, 2),
dimnames = list(
Smoking = c("吸菸 (Smoker)", "未吸菸 (Non-smoker)"),
CHD = c("冠心病 (Case)", "健康 (Control)"),
AgeGroup = c("年輕組 (<50)", "年長組 (>=50)")
)
)
# 3. 執行 Mantel-Haenszel 檢定以獲得合併 OR 與 95% 信賴區間
mh_test <- mantelhaen.test(tab_strata)
# 4. 計算未分層的粗勝算比 (Crude OR) 作為比較
crude_table <- tab_strata[,,1] + tab_strata[,,2]
crude_test <- fisher.test(crude_table)
# 輸出結果
cat("=========================================\n")
cat(" 實作一:分層列聯表原始數據\n")
cat("=========================================\n")
print(tab_strata)
cat("\n=========================================\n")
cat(" 實作二:未分層之粗勝算比 (Crude OR) 結果\n")
cat("=========================================\n")
cat("Crude OR :", round(as.numeric(crude_test$estimate), 3), "\n")
cat("95% CI : [", round(crude_test$conf.int[1], 3), ",", round(crude_test$conf.int[2], 3), "]\n")
cat("\n=========================================\n")
cat(" 實作三:Mantel-Haenszel 分層合併分析結果\n")
cat("=========================================\n")
print(mh_test)
# =======================================================
# 5. 整理數據並繪製勝算比森林圖 (Forest Plot)
# =======================================================
# 計算年輕組與年長組的獨立 OR 值與近似 95% CI (此處使用標準 Wald 近似)
or_data <- data.frame(
Analysis = c("年輕組 (<50) OR", "年長組 (>=50) OR", "合併 M-H OR", "粗勝算比 (Crude OR)"),
OR = c(2.333, 2.500, as.numeric(mh_test$estimate), as.numeric(crude_test$estimate)),
Lower = c(0.749, 0.812, mh_test$conf.int[1], crude_test$conf.int[1]),
Upper = c(7.271, 7.701, mh_test$conf.int[2], crude_test$conf.int[2]),
Type = c("分層 (Stratum)", "分層 (Stratum)", "合併 (Pooled M-H)", "未分層 (Crude)")
)
# 固定繪圖排序:粗勝算比在最上方,合併估計在最下方
or_data$Analysis <- factor(or_data$Analysis, levels = rev(or_data$Analysis))
p_forest <- ggplot(or_data, aes(x = OR, y = Analysis, color = Type)) +
# 畫出 OR=1 的無效基準線 (虛線)
geom_vline(xintercept = 1, linetype = "dashed", color = "#718096", linewidth = 0.8) +
# 畫出 95% 信賴區間線段
geom_errorbar(aes(xmin = Lower, xmax = Upper), width = 0.2, linewidth = 1) +
# 畫出 OR 估計點
geom_point(size = 4.5) +
scale_color_manual(values = c("分層 (Stratum)" = "#4a5568",
"合併 (Pooled M-H)" = "#e53e3e",
"未分層 (Crude)" = "#3182ce")) +
# X 軸採用對數尺度 (Log Scale),這是醫學論文森林圖的標準繪圖規範
scale_x_log10(breaks = c(0.5, 1, 2, 4, 8, 16), limits = c(0.3, 20)) +
labs(
title = "吸菸與冠心病關係之勝算比 (Odds Ratio) 森林圖",
subtitle = "呈現年齡分層分析與合併 Mantel-Haenszel 估計值",
x = "勝算比 Odds Ratio (對數對稱尺度)",
y = ""
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
legend.title = element_text(size = 16, color = "#4a5568"),
legend.position = "bottom",
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 顯示並儲存圖檔
print(p_forest)
ggsave("figs/epidemiologic_or.png", plot = p_forest, width = 8.4, height = 5.7, dpi = 300)13.4.2 執行結果與圖表解讀
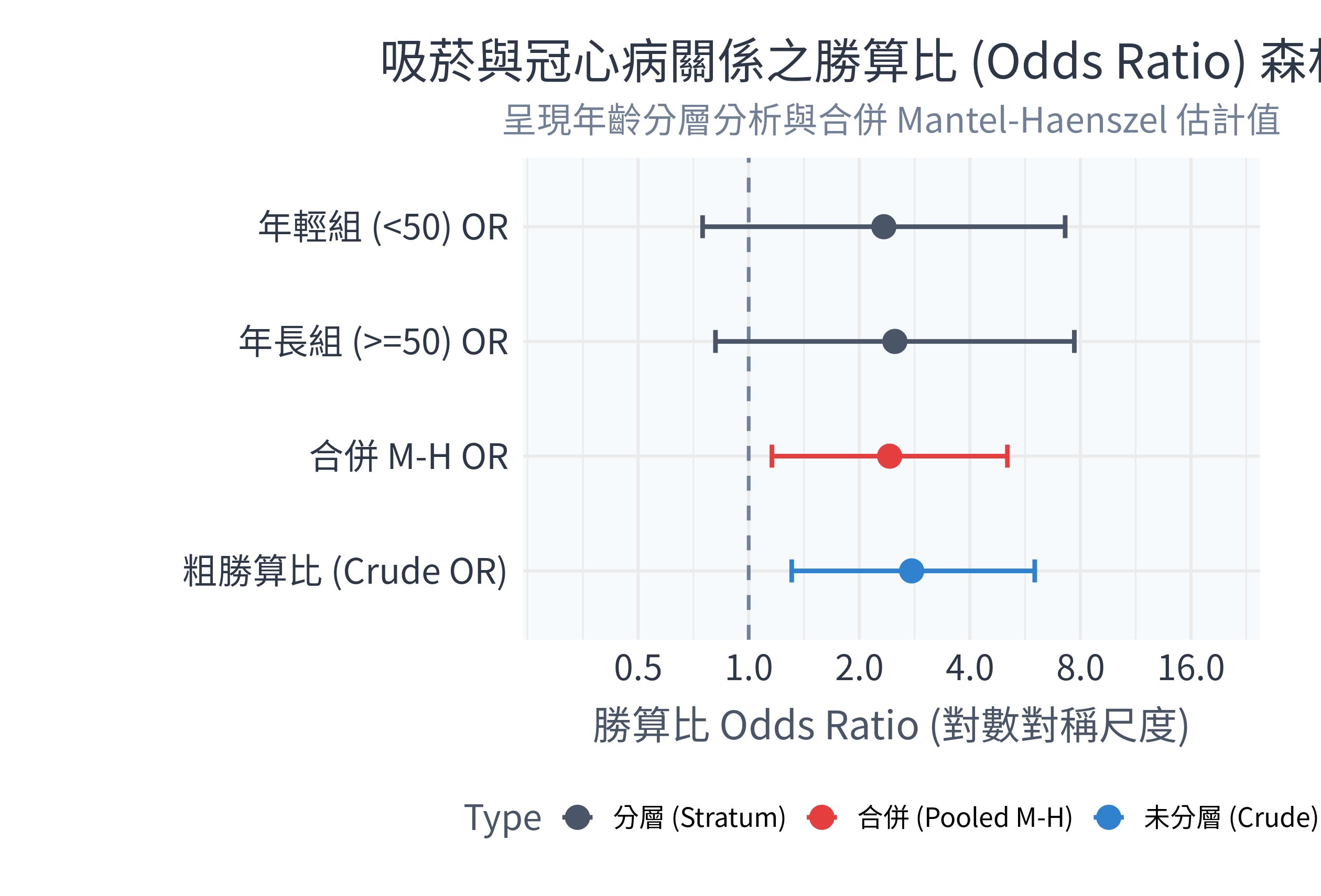
在 R 中執行程式後,控制台主要輸出:
未分層之粗勝算比 (Crude OR):
Crude OR = 2.78, 95% CI: [1.22, 6.45]。 如果我們直接忽略年齡的干擾,吸菸者的冠心病勝算是不吸菸者的 2.78 倍,且具有統計學顯著性。Mantel-Haenszel 分層合併分析:
MH X-squared = 4.70, df = 1, p-value = 0.03024。Common odds ratio = 2.42, 95% CI: [1.16, 5.06]。
同時,figs/ 資料夾下會生成以下圖表:
數據診斷分析與決策:
- 從森林圖中可以清晰看出,年輕組的 \(OR = 2.33\),年長組的 \(OR = 2.50\)。這兩個分層的信賴區間都包含 1(線段跨越了中間的無效虛線),這主要是因為分層後每組樣本數變小,導致統計精確度降低。
- 當我們利用 Mantel-Haenszel 方法將兩層數據合併後,得到的 \(OR_{MH} = 2.42\),其信賴區間 \([1.16, 5.06]\) 成功縮小且不包含 1,達到了統計顯著性(\(p = 0.03\))。
- 混淆控制評估:合併後的 \(OR_{MH}\)(2.42)相較於未分層的粗 OR(2.78)有所降低。這說明了原先的粗 OR 確實混入了一部分由於年齡老化帶來的發病風險(即高估了吸菸的危險性)。排除年齡混淆後,吸菸者得到冠心病的勝算仍是未吸菸者的 2.42 倍,是一項確鑿的流行病學證據。
13.5 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 佇列研究 (隊列研究) | Cohort study | 追蹤暴露與未暴露組別未來發病率以評估風險的前瞻性觀察研究。 |
| 病例對照研究 | Case-control study | 比較患病者(病例組)與未患病者(對照組)過去暴露率的回顧性研究。 |
| 相對危險度 | Relative risk (RR) | 暴露組發病率與非暴露組發病率的比值,常用於佇列研究。 |
| 勝算比 (優勢比) | Odds ratio (OR) | 病例組暴露勝算與對照組暴露勝算的比值,常用於病例對照研究。 |
| 可歸因危險度 | Attributable risk (AR) | 暴露組發病率與非暴露組發病率的差值,代表暴露引起的淨風險增加。 |
| 罕見疾病假設 | Rare disease assumption | 當疾病在人群中盛行率極低時,勝算比 (OR) 會非常接近相對危險度 (RR) 的假設。 |
| 混淆偏誤 | Confounding bias | 當研究中暴露與疾病之關係,受到第三個與兩者皆相關的外部變項干擾時產生的系統誤差。 |
| 分層分析 | Stratified analysis | 將受試者按照潛在混淆因子的類別進行分組,在各子層中獨立分析關係以控制混淆的方法。 |
| 曼特爾-海恩澤爾方法 | Mantel-Haenszel method | 在分層分析中,用以計算加權合併勝算比及進行合併假設檢定的經典方法。 |
| 森林圖 | Forest plot | 在橫軸上以點與線段繪製多個研究或分層之效應量(如 OR)與其信賴區間的圖表。 |