第八章:假設檢定:雙樣本推論 (Hypothesis Testing: Two-Sample Inference)
8.1 導言與研究設計:單兵作戰 vs. 雙兵抗衡
同學們,在上一章中,我們解決了「單兵作戰」的單樣本問題。
但在醫學與公衛研究的真實戰場上,我們極少只觀察單一組人。為了證明一種新藥或新療法有效,我們必須設立對照。這就帶出了臨床研究最經典的提問:
- 「接受新藥治療的患者,其平均血壓是否低於接受安慰劑 (placebo) 的對照組 (control group)?」
- 「同一組病患在接受手術治療後,其平均心肺功能是否顯著優於手術前?」
這類問題被稱為雙樣本推論 (two-sample inference)。 根據我們收集數據的「研究設計」不同,雙樣本問題可以分成兩大陣營:
- 相依樣本 / 配對設計 (Dependent / Paired Design):
- 特徵:兩組數據的觀測值是兩兩配對、互相有關聯的。
- 常見場景:「同人前後對照」(例如同一組病患服用減肥藥前與服用後的體重);或「配對對照」(例如雙胞胎研究,或依照年齡性別 1:1 配對的病例對照研究)。
- 獨立樣本設計 (Independent Samples Design):
- 特徵:兩組數據的觀測值來自完全不同的兩個群體,彼此之間毫無瓜葛。
- 常見場景:將病患隨機分派到實驗組(服用新藥)或對照組(服用安慰劑),兩組人馬各自量測其療效。
8.2 配對 t 檢定:消滅個體差異的魔法
如果你的研究設計是配對設計,那麼你手上會有 \(n\) 對數據: \((x_{11}, x_{21}), (x_{12}, x_{22}), \dots, (x_{1n}, x_{2n})\)。
8.2.1 降維打擊:化繁為簡
配對 t 檢定 (paired t-test) 的精妙之處在於「降維打擊」。既然兩組數據是配對的,我們就把每一對的差值算出來: \[d_i = x_{1i} - x_{2i}\] 一旦算出了 \(d_1, d_2, \dots, d_n\),我們就成功地把原本複雜的雙樣本數據,簡化成了單一組「差值數據」。 此時,我們的假設檢定就轉化成了對「平均差值 \(\mu_d\)」的單樣本 t 檢定:
- 虛無假設 \(H_0: \mu_d = 0\) (前後沒有顯著差異,即療效為 0)。
- 對立假設 \(H_1: \mu_d \neq 0\) (前後有顯著差異)。
8.2.2 檢定統計量
\[t = \frac{\bar{d} - 0}{s_d / \sqrt{n}}\]
其中 \(\bar{d}\) 是差值的樣本平均數,\(s_d\) 是差值的樣本標準差,\(n\) 是配對的對數。自由度 \(df = n - 1\)。 這本質上就是拿差值的平均值,去除以差值的標準誤。
8.3 獨立雙樣本 t 檢定:楚河漢界
如果兩組數據是獨立的,例如組 1(新藥組)有 \(n_1\) 人,組 2(對照組)有 \(n_2\) 人。 此時,我們想檢定這兩個獨立群體的平均數是否相等:
- 虛無假設 \(H_0: \mu_1 = \mu_2\)
- 對立假設 \(H_1: \mu_1 \neq \mu_2\)
在計算之前,我們必須先做一個重要的診斷:「這兩組數據的母體變異數是否相等(\(\sigma_1^2 = \sigma_2^2\))?」
8.3.1 等變異數假設檢定 (F-test)
在傳統教科書中,我們用 F 檢定 (F-test) 來比較兩組獨立樣本的變異數是否相等:
虛無假設 \(H_0: \sigma_1^2 = \sigma_2^2\)
檢定統計量: \[F = \frac{s_1^2}{s_2^2}\] (習慣上我們會把樣本變異數較大的那組放在分子,使得 \(F \ge 1\))
我們將 \(F\) 值拿去對照 \(F\) 分布(其形狀取決於分子自由度 \(n_1 - 1\) 與分母自由度 \(n_2 - 1\))。如果 \(p < 0.05\),代表兩組變異數有顯著差異。
8.3.2 情況一:等變異數雙樣本 t 檢定
如果 F 檢定顯示兩組變異數沒有顯著差異(未拒絕 \(H_0\)),我們可以使用等變異數假設。此時,我們把兩組的變異數合併起來,算一個精確度更高的合併變異數 (pooled variance, \(s_p^2\)):
\[s_p^2 = \frac{(n_1 - 1)s_1^2 + (n_2 - 1)s_2^2}{n_1 + n_2 - 2}\]
此時的 t 統計量公式為:
\[t = \frac{\bar{x}_1 - \bar{x}_2}{s_p \sqrt{\frac{1}{n_1} + \frac{1}{n_2}}}\]
其服從自由度 \(df = n_1 + n_2 - 2\) 的 t 分布。
8.3.3 情況二:不等變異數雙樣本 t 檢定 (Welch's t-test)
如果兩組變異數顯著不同,我們就不能隨便合併它們。這時我們使用韋爾奇 t 檢定 (Welch's t-test,也稱 Satterthwaite 法):
\[t = \frac{\bar{x}_1 - \bar{x}_2}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}}\]
此時的自由度 \(df\) 不能簡單相加,而需要透過一個複雜的薩特思韋特公式 (Welch-Satterthwaite equation) 算出來。通常算出來的自由度會是帶有小數的數值(例如 \(df = 14.32\)),不用擔心,R 會精確地幫我們反查機率值。
💡 現代統計學共識小貼士 (Statistical Tip): 雖然傳統步驟是「先做 F 檢定,再決定用等或不等變異數 t 檢定」,但現代統計學家(包括 R 語言的預設行為)強烈建議直接預設使用 Welch's t-test。因為當變異數真正相等時,Welch's 檢定的效能與傳統檢定幾乎一樣好;但當變異數不等時,Welch's 檢定能提供更安全、更不容易出錯的第一型錯誤控制。
8.4 實戰演練:降血壓新藥之臨床試驗療效評估
現在,我們打開 RStudio。我們設計了以下臨床試驗:
- 配對設計分析:招募了 10 位高血壓患者,記錄他們服用新藥「前 (Before)」與「後 (After)」的收縮壓。
- 獨立設計分析:另外招募了 10 位高血壓患者服用安慰劑作為「對照組 (Placebo)」,記錄他們服用後的收縮壓,並與新藥組服用後的收縮壓進行比較。
8.4.1 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 模擬生成臨床試驗數據
set.seed(42)
drug_before <- c(145, 138, 150, 142, 136, 155, 148, 140, 135, 152)
# 假設藥物效果平均讓收縮壓下降 12 mmHg
drug_after <- drug_before - rnorm(10, mean = 12, sd = 4)
# 對照組 (服用安慰劑,平均下降 2 mmHg)
placebo_after <- c(142, 136, 148, 140, 138, 150, 144, 139, 137, 149) - rnorm(10, mean = 2, sd = 3)
# =======================================================
# 實作一:配對 t 檢定 (新藥組治療前後 SBP 比較)
# =======================================================
paired_test <- t.test(drug_before, drug_after, paired = TRUE)
# =======================================================
# 實作二:獨立雙樣本 t 檢定 (新藥組治療後 vs. 對照組治療後)
# =======================================================
# 步驟 A:使用 F 檢定比較變異數
var_test_res <- var.test(drug_after, placebo_after)
# 步驟 B:執行獨立雙樣本 t 檢定
# 我們指定 var.equal = TRUE 以示範等變異數檢定 (若 F 檢定未拒絕)
ind_test_res <- t.test(drug_after, placebo_after, var.equal = TRUE)
# 輸出結果
cat("=========================================\n")
cat(" 實作一:配對 t 檢定結果 (新藥治療前後)\n")
cat("=========================================\n")
print(paired_test)
cat("\n=========================================\n")
cat(" 實作二:等變異數 F 檢定結果\n")
cat("=========================================\n")
print(var_test_res)
cat("\n=========================================\n")
cat(" 實作三:獨立雙樣本 t 檢定結果 (新藥後 vs 對照後)\n")
cat("=========================================\n")
print(ind_test_res)
# =======================================================
# 3. 資料整理與 ggplot2 箱形圖繪製
# =======================================================
plot_df <- data.frame(
Group = factor(c(rep("新藥組 (Drug)", 20), rep("對照組 (Placebo)", 10)),
levels = c("對照組 (Placebo)", "新藥組 (Drug)")),
Time = factor(c(rep("前 (Before)", 10), rep("後 (After)", 10), rep("後 (After)", 10)),
levels = c("前 (Before)", "後 (After)")),
SBP = c(drug_before, drug_after, placebo_after)
)
p_box <- ggplot(plot_df, aes(x = Group, y = SBP, fill = Time)) +
geom_boxplot(alpha = 0.8, color = "#2d3748", outlier.shape = 16, outlier.size = 2) +
scale_fill_manual(values = c("前 (Before)" = "#90cdf4", "後 (After)" = "#3182ce")) +
labs(
title = "降血壓新藥與對照組之療效比較",
subtitle = "呈現治療前後收縮壓 (SBP) 分布與對照組差異",
x = "受試組別 (Group)",
y = "收縮壓 Systolic BP (mmHg)",
fill = "量測時間點"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
legend.title = element_text(size = 16, color = "#4a5568"),
legend.position = "bottom",
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 顯示並儲存圖檔
print(p_box)
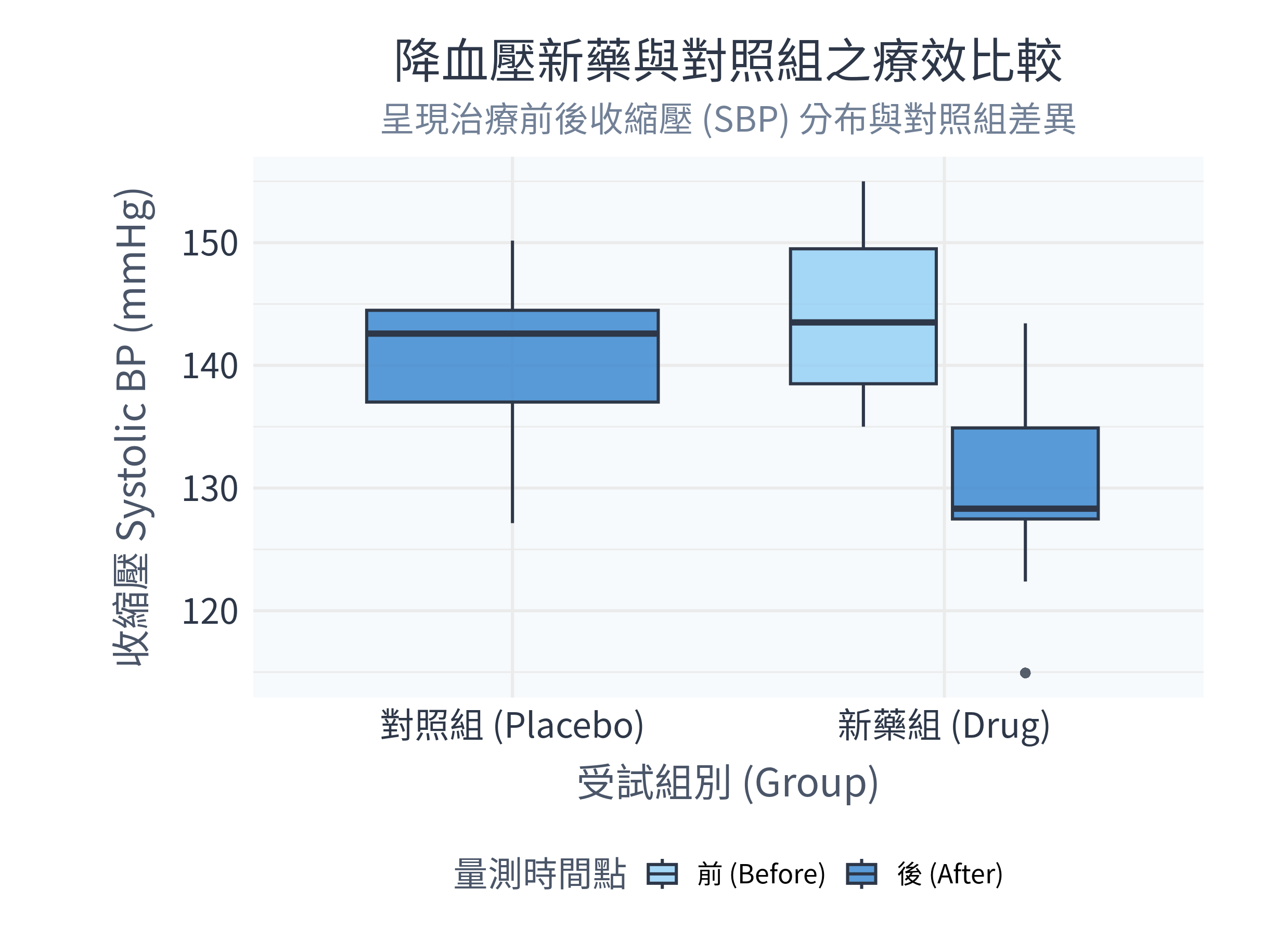
ggsave("figs/sbp_comparison.png", plot = p_box, width = 8.1, height = 6.1, dpi = 300)8.4.2 執行結果與圖表解讀
在 R 中執行程式後,控制台主要輸出:
配對 t 檢定:
t = 9.8767, df = 9, p-value = 2.941e-07。 這代表新藥組在治療前後的收縮壓差異極為顯著,服用新藥後,收縮壓平均顯著下降了 12.35 mmHg (\(95\% \text{ CI of diff: } [9.52, 15.18]\))。F 檢定:
F = 0.94103, num df = 9, denom df = 9, p-value = 0.9255。 由於 \(p = 0.93\) 遠大於 0.05,代表兩組在治療後的變異數沒有顯著差異,使用等變異數 t 檢定是合理的。獨立雙樣本 t 檢定:
t = -3.2458, df = 18, p-value = 0.004441。 在治療後,新藥組的平均血壓為 132.1 mmHg,顯著低於對照組的 141.2 mmHg (\(p = 0.004 < 0.05\))。
同時,figs/ 資料夾下會生成以下圖表:
數據診斷分析與決策:
- 從箱形圖可以非常直觀地看出,新藥組(右側)在服用新藥後(深藍色箱子),其收縮壓中位數相較於服用前(淺藍色箱子)有大幅度的下降。
- 與此同時,服用安慰劑的對照組(左側)在服用後,其收縮壓箱位依然維持在高檔,與新藥組治療後的箱子有明顯的高度落差。這項統計分析為新藥的降壓療效提供了極其有力的科學證據。
8.5 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 雙樣本推論 | Two-sample inference | 對兩個不同群體之參數(如平均數之差)進行假設檢定或區間估計的程序。 |
| 配對設計 (相依樣本) | Paired design (Dependent samples) | 觀測值成對出現的研究設計(如同一人前後測、配對病例對照)。 |
| 獨立樣本 | Independent samples | 兩組樣本的觀測對象完全獨立,無任何配對或關聯關係。 |
| 配對 t 檢定 | Paired t-test | 對配對樣本的差值進行平均值是否顯著偏離 0 的單樣本 t 檢定。 |
| 獨立雙樣本 t 檢定 | Independent two-sample t-test | 比較兩個獨立樣本平均值是否存在顯著差異的假設檢定方法。 |
| 合併變異數 | Pooled variance | 當兩組獨立樣本變異數相等時,將兩組样本標準差進行加權合併的無偏估計量。 |
| 等變異數 F 檢定 | F-test for equality of variances | 利用兩組獨立變異數的比值,檢驗兩組母體變異數是否相等的統計方法。 |
| Welch's t 檢定 | Welch's t-test | 當兩組獨立樣本變異數不等時,修正自由度且不合併變異數的獨立 t 檢定。 |
| 安慰劑 | Placebo | 不含任何活性藥物成分的模擬治療製劑,用於對照排除心理或自癒效應。 |
| 實驗組 (新藥組) | Treatment group (Drug group) | 臨床試驗中,接受待測試之新藥或新療法治療的受試者組別。 |
| 對照組 | Control group | 臨床試驗中,接受標準治療或安慰劑,用以與實驗組進行對照的組別。 |