第七章:假設檢定:單樣本推論 (Hypothesis Testing: One-Sample Inference)
7.1 導言與假設檢定基本架構:法庭上的「無罪推定」
同學們,在上一章中,我們學會了如何給未知母體參數估計出一個範圍(信賴區間)。但有時候,臨床人員不想只知道「範圍」,而是要做出明確的二分法決策:
- 「這種新開發的感冒疫苗,到底有防護效果,還是沒效果?」
- 「我們病房的高血壓患者,平均收縮壓是否顯著高於健康人的標準 120 mmHg?」
這種透過樣本證據來對母體參數的某個宣稱進行決策的過程,就叫做假設檢定 (hypothesis testing)。
為了做出客觀的決定,統計學家設計了一套類似「法庭審判」的邏輯。法庭審判遵循「無罪推定原則」,在有足夠證據定罪之前,被告都被視為無罪。在假設檢定中,我們也有兩個對立的假說:
- 虛無假設 (Null Hypothesis, 記為 \(H_0\)):
- 相當於法庭上的「被告無罪」。
- 代表現狀、「沒有差別」、「沒有療效」、「一切純屬隨機誤差」。
- 例如: \(H_0: \mu = 120\) (患者平均收縮壓與正常值 120 mmHg 沒有差別)。
- 對立假設 (Alternative Hypothesis, 記為 \(H_1\)):
- 相當於法庭上的「被告有罪」。
- 代表我們真正想證明的科學宣稱——「有顯著差別」、「有療效」。
- 例如: \(H_1: \mu \neq 120\) (患者平均收縮壓與正常值有顯著差別)。
我們的檢定規則是:「除非有非常強力的样本證據,否則我們不會輕易推翻虛無假設 \(H_0\)。」
7.2 決策的代價:兩型錯誤與檢定力
既然是用樣本來推估母體,只要有抽樣,就一定有可能做錯決定。就像法官審判一樣,可能會冤枉好人,也可能會放走壞人。
在統計學上,我們用一個二維的決策表格來衡量這兩類錯誤:
| 真實情況 統計決策 | 未推翻 \(H_0\) (宣判無罪) | 推翻 \(H_0\) / 拒絕 \(H_0\) (宣判有罪) |
|---|---|---|
| \(H_0\) 為真 (被告真正無罪) | 正確決策 (\(1 - \alpha\)) | 第一型錯誤 (Type I Error, \(\alpha\)) (冤獄:沒病判有病) |
| \(H_0\) 為假 (被告真正有罪) | 第二型錯誤 (Type II Error, \(\beta\)) (縱囚:有病判沒病) |
正確決策——檢定力 (Power, \(1 - \beta\)) (正義伸張:揪出真有病者) |
- 第一型錯誤 (Type I Error, \(\alpha\)):
- 定義:當虛無假設 \(H_0\) 其實是真的,我們卻拒絕了它(冤枉好人)。
- 機率:通常用 \(\alpha\)(顯著水準)表示,臨床研究中常人為限制在 5% (\(\alpha = 0.05\))。這代表我們願意承受「最多 5% 的風險去冤枉新藥有效」。
- 第二型錯誤 (Type II Error, \(\beta\)):
- 定義:當虛無假設 \(H_0\) 其實是假的,我們卻沒有推翻它(縱放壞人)。
- 機率:通常用 \(\beta\) 表示。
- 檢定力 (Power, \(1 - \beta\)):
- 定義:當對立假設 \(H_1\) 為真時,我們正確拒絕 \(H_0\) 的機率(成功抓出壞人、驗證療效的能力)。
- 醫學研究中,一般要求檢定力至少要達到 80% (\(1-\beta = 0.80\)) 以上。
7.3 p 值的真實含意
當你翻開任何一本醫學期刊,滿眼都是「\(p < 0.05\) 具有統計顯著性(statistically significant)」。
那麼,p 值 (p-value) 的科學定義到底是什麼?
💡 教授的觀念小考:p 值的定義 p 值是在「假定虛無假設 \(H_0\) 為真」的前提下,我們所收集到的樣本數據(或比它更極端的值)出現的機率。
- 如果 \(p\) 值很小(例如 \(p = 0.001\)):代表在 \(H_0\)(沒有療效)為真的世界中,我們的樣本結果簡直是「奇蹟」,發生的機率只有千分之一。既然奇蹟很少發生,我們合理的推論就是—— \(H_0\)(沒有療效)大概是錯的,我們應當拒絕 \(H_0\)。
- 如果 \(p\) 值很大(例如 \(p = 0.40\)):代表即使 \(H_0\) 為真,這種樣本結果也很稀鬆平常。我們沒有足夠的證據來推翻 \(H_0\)。
7.4 單樣本 t 檢定
當我們要檢定一個連續型隨機變項的平均數 \(\mu\),是否與某個已知的對照常數 \(\mu_0\) 存在顯著差異,且母體標準差未知時,我們使用單樣本 t 檢定 (one-sample t-test)。
7.4.1 檢定的五大步驟
建立假設:
- 雙尾檢定: \(H_0: \mu = \mu_0\) vs \(H_1: \mu \neq \mu_0\)
設定顯著水準: 通常取 \(\alpha = 0.05\)。
計算檢定統計量: \[t = \frac{\bar{x} - \mu_0}{s/\sqrt{n}}\] 這個 \(t\) 值本質上就是「我們的樣本平均數距離虛無假設 \(\mu_0\) 有幾個標準誤(SEM)的距離」。
決定拒絕域或臨界值: 在自由度 \(df = n - 1\) 的 \(t\) 分布下,雙尾檢定的臨界值 (critical value) 為 \(\pm t_{df, 1-\alpha/2}\)。
- 若我們的 \(|t| > t_{\text{臨界值}}\),代表統計量落入了拒絕域 (rejection region),此時拒絕 \(H_0\)。
得出臨床結論: 寫出是否拒絕 \(H_0\),並給出 \(p\) 值與統計顯著性說明。
7.5 實戰演練:高血壓患者平均血壓檢定
現在,我們打開 RStudio。假設我們收集了 15 位特定病房患者的收縮壓數據(如下代碼所示),我們想檢定這群患者的平均收縮壓,是否顯著偏離了健康的標準值 120 mmHg。
7.5.1 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 輸入 15 位病患的收縮壓數據 (mmHg)
set.seed(42)
sbp_data <- c(125, 138, 130, 142, 120, 135, 145, 128, 132, 140, 122, 134, 148, 118, 126)
# 3. 設定檢定基準值 H0: mu = 120
mu_0 <- 120
n <- length(sbp_data)
mean_sbp <- mean(sbp_data)
sd_sbp <- sd(sbp_data)
sem_sbp <- sd_sbp / sqrt(n)
# 4. 手動計算 t 統計量與 p 值
t_stat <- (mean_sbp - mu_0) / sem_sbp
df_val <- n - 1
p_val_manual <- 2 * (1 - pt(abs(t_stat), df = df_val)) # 雙尾檢定 p 值
# 5. 使用 R 內建 t.test() 函數進行驗證
t_test_res <- t.test(sbp_data, mu = mu_0)
# 印出檢定結果
cat("--- 單樣本 t 檢定手動計算結果 ---\n")
cat("樣本平均數 (Mean) :", round(mean_sbp, 3), "mmHg\n")
cat("樣本標準差 (SD) :", round(sd_sbp, 3), "mmHg\n")
cat("平均數標準誤 (SEM) :", round(sem_sbp, 3), "mmHg\n")
cat("t 檢定統計量 (t-statistic):", round(t_stat, 3), "\n")
cat("自由度 (df) :", df_val, "\n")
cat("雙尾 p 值 (p-value) :", round(p_val_manual, 6), "\n")
cat("---------------------------------\n\n")
print(t_test_res)
# =======================================================
# 6. 使用 ggplot2 繪製 t 分布圖,標出拒絕域與我們的 t 統計量位置
# =======================================================
x_vals <- seq(-6, 6, length.out = 1000)
y_vals <- dt(x_vals, df = df_val)
t_df <- data.frame(t_val = x_vals, Density = y_vals)
# 計算 alpha = 0.05 雙尾檢定的 t 臨界值
alpha <- 0.05
t_crit <- qt(1 - alpha/2, df = df_val)
# 篩選左右兩側拒絕域以利塗色
df_rej_left <- subset(t_df, t_val < -t_crit)
df_rej_right <- subset(t_df, t_val > t_crit)
p_hypo <- ggplot(t_df, aes(x = t_val, y = Density)) +
geom_line(color = "#4a5568", linewidth = 1) +
# 塗色左、右拒絕域 (紅色)
geom_area(data = df_rej_left, aes(y = Density), fill = "#e53e3e", alpha = 0.5) +
geom_area(data = df_rej_right, aes(y = Density), fill = "#e53e3e", alpha = 0.5) +
# 畫出臨界值虛線
geom_vline(xintercept = c(-t_crit, t_crit), linetype = "dashed", color = "#e53e3e", linewidth = 0.8) +
# 畫出我們的樣本 t 統計量位置 (藍色實線)
geom_vline(xintercept = t_stat, color = "#2b6cb0", linewidth = 1.2) +
annotate("text", x = t_stat - 1.2, y = 0.25,
label = paste0("樣本統計量\nt = ", round(t_stat, 2)),
size = 6.2, color = "#2b6cb0", family = "Noto Sans CJK TC", fontface = "bold") +
annotate("text", x = t_crit + 1.1, y = 0.05,
label = paste0("右側拒絕域\nt > ", round(t_crit, 2)),
size = 5.8, color = "#9b2c2c", family = "Noto Sans CJK TC") +
annotate("text", x = -t_crit - 1.1, y = 0.05,
label = paste0("左側拒絕域\nt < -", round(t_crit, 2)),
size = 5.8, color = "#9b2c2c", family = "Noto Sans CJK TC") +
labs(
title = "單樣本 t 檢定之拒絕域與檢定統計量位置",
subtitle = paste0("自由度 df = ", df_val, ", 顯著水準 alpha = 0.05 (雙尾檢定)"),
x = "t 值 (t-value)",
y = "機率密度 Probability Density"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請更換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 顯示並儲存圖表
print(p_hypo)
ggsave("figs/t_test_rejection.png", plot = p_hypo, width = 8.1, height = 5.7, dpi = 300)7.5.2 執行結果與圖表解讀
在 R 中執行程式後,控制台會輸出:
One Sample t-test
data: sbp_data
t = 5.1408, df = 14, p-value = 0.0001476
alternative hypothesis: true mean is not equal to 120
95 percent confidence interval:
126.6579 135.0754
sample estimates:
mean of x
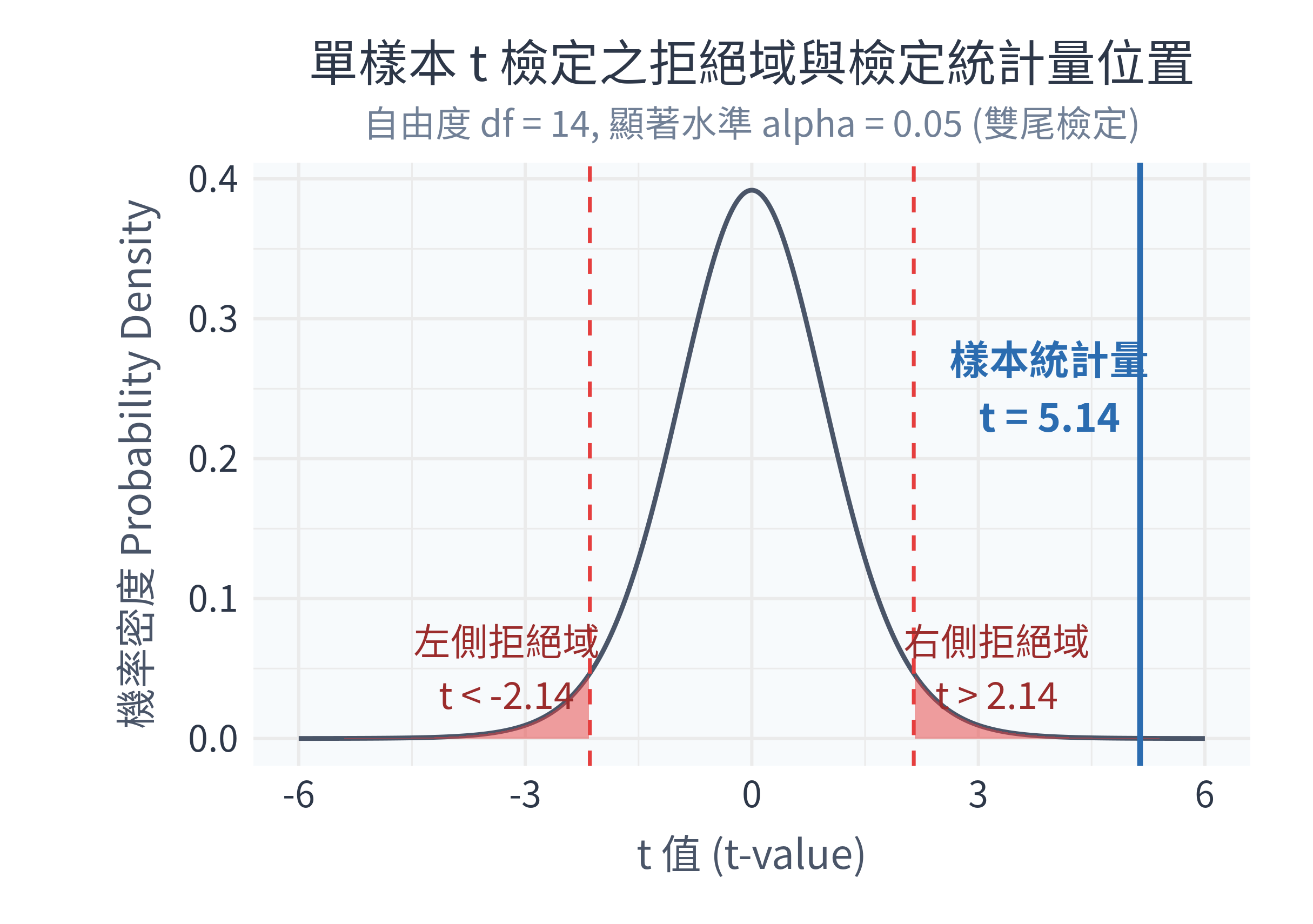
130.8667同時,figs/ 資料夾下會生成以下圖表:
數據診斷分析與決策:
- 假設檢定決策:我們的顯著水準 \(\alpha = 0.05\),對應的雙尾臨界值為 \(\pm 2.145\)。而我們算出的樣本檢定統計量為 \(t = 5.14\),遠遠超出了臨界值,掉進了極深處的右側拒絕域(紅色區塊)。
- p 值的臨床解讀:算出的 \(p\) 值為 0.00015 (\(p < 0.05\))。這代表如果這群病人的真實平均血壓真的是 120 mmHg (\(H_0\) 為真),那麼要隨機抽樣到平均收縮壓為 130.87 mmHg 的機率,只有十萬分之十五!
- 結論:因為證據極為強烈,我們拒絕虛無假設 \(H_0\),接受對立假設 \(H_1\)。結論為:這群病患的平均收縮壓顯著高於健康標準 120 mmHg,且具有極高度的統計學顯著性。
7.6 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 假設檢定 | Hypothesis testing | 根據樣本觀測資料的證據,決定是否拒絕關於母體參數某項假設的統計方法。 |
| 虛無假設 (零假設) | Null hypothesis (\(H_0\)) | 代表「沒有差別」、「沒有效應」或「現狀」的假設,檢定時預設其成立。 |
| 對立假設 (備擇假設) | Alternative hypothesis (\(H_1\)) | 與虛無假設對立的假設,通常是研究者想要證明有差別或有效應的科學宣稱。 |
| 第一型錯誤 (偽陽性) | Type I error | 當虛無假設實際上為真時,我們卻錯誤地拒絕了它(冤枉好人)。 |
| 顯著水準 | Significance level (\(\alpha\)) | 人為設定的第一型錯誤最大容忍機率(通常為 0.05),也是拒絕域的面積界限。 |
| 第二型錯誤 (偽陰性) | Type II error (\(\beta\)) | 當虛無假設實際上為假時,我們卻錯誤地沒有拒絕它(縱放壞人)。 |
| 檢定力 (統計功效) | Power | 當對立假設為真時,檢定方法能正確拒絕虛無假設的機率 (\(1 - \beta\))。 |
| p 值 | p-value | 在虛無假設為真的假設下,得到與觀測樣本相同或更極端統計量數值的機率。 |
| 統計顯著性 | Statistical significance | 當 p 值小於設定的顯著水準(通常為 0.05)時,稱結果具有統計顯著性。 |
| 單樣本 t 檢定 | One-sample t-test | 檢定單一連續變項的樣本平均數與某個指定常數之間是否存在顯著差異的 t 檢定。 |
| 檢定統計量 | Test statistic | 用來進行假設檢定決策的樣本計算指標(如 t 值、Z 值)。 |
| 拒絕域 (臨界區域) | Rejection region | 在假設下,檢定統計量極不可能落入的數值區域。若落入此區,則拒絕虛無假設。 |
| 臨界值 | Critical value | 劃分接受域與拒絕域的邊界統計量數值(如 \(\pm 2.145\))。 |
| 雙尾檢定 | Two-sided test / Two-tailed test | 對立假設只宣稱有差別(大於或小於)時,在分布左右兩側均設有拒絕域的檢定。 |
| 單尾檢定 | One-sided test / One-tailed test | 對立假設宣稱有特定方向性(限大於或限小於)時,只在單側設有拒絕域的檢定。 |