第三章:機率論 (Probability)
3.1 導言:臨床決策中的「水晶球」
同學們,在前面兩章,我們學會了如何收集患者的數據並整理它們。但當你真正穿上白袍開始看診時,你會發現醫學世界最令人頭痛的特質就是:不確定性。
想像一下:
- 一位患者來找你,他有輕微咳嗽。你怎麼知道他得的是普通感冒,還是新冠肺炎?
- 你幫一位孕婦做唐氏症篩檢,結果呈現「陽性」。這代表寶寶有唐氏症的機率是一百趴嗎?
- 某種新手術的成功率是 90%。如果前面 9 個病人都成功了,第 10 個病人是不是死定了?(先劇透:絕對不是!)
面對這些臨床上的未知,我們沒有魔法水晶球,但我們有數學界的超能力——機率論 (probability)。 機率就是「將不確定性量化」的工具。學好機率,你才能在診間冷靜地面對各種檢驗報告,給出最科學的診斷,而不是像算命仙一樣瞎猜。
3.2 機率的基本概念與規則
在進入醫學應用前,我們得先學會機率的「遊戲規則」。
3.2.1 什麼是機率?
在統計學上,我們把一個過程(例如丟骰子、做篩檢)稱為試驗 (experiment)。
- 樣本空間 (sample space, 通常記為 \(S\)):一個試驗所有可能結果的集合。例如丟一個硬幣,\(S = \{反面, 正面\}\)。
- 事件 (event, 通常用大寫字母 \(A, B\) 表示):樣本空間中的一部分結果。例如「抽血結果是高血脂」。
一個事件 \(A\) 發生的機率 \(P(A)\),數值一定介於 0 與 1 之間: \[0 \le P(A) \le 1\]
- \(P(A) = 0\) 代表絕對不會發生(例如:不打疫苗且不接觸病毒卻突然憑空產生抗體)。
- \(P(A) = 1\) 代表百分之百發生(例如:人活著就一定會面臨細胞衰老)。
3.2.2 事件的關係:互斥 vs. 獨立
這兩個概念是初學者最容易搞混的「世紀大坑」,請大家睜大眼睛看清楚了:
- 互斥事件 (mutually exclusive events):
- 定義:兩個事件「絕對不可能同時發生」。
- 例子:一位病患此時此刻的流感篩檢結果,不可能「既是陽性又是陰性」。
- 公式(加法規則):如果事件 \(A\) 與 \(B\) 互斥,那麼 \(A\) 或 \(B\) 發生的機率為: \[P(A \cup B) = P(A) + P(B)\]
- 獨立事件 (independent events):
- 定義:一個事件的發生,「完全不會影響」另一個事件發生的機率。
- 例子:今天診間第一位病人得流感(事件 \(A\)),完全不會影響第二位門診病人是否得流感(事件 \(B\))(假設他們不是住在一起的家人)。
- 公式(乘法規則):如果事件 \(A\) 與 \(B\) 獨立,那麼 \(A\) 與 \(B\) 同時發生的機率為: \[P(A \cap B) = P(A) \times P(B)\]
3.3 條件機率:如果...那又怎樣?
在醫學上,我們幾乎不會單獨詢問一個無條件的機率。我們更常問的是: 「如果已知病人的電腦斷層掃描看到陰影(條件),那麼他得肺癌的機率是多少?」
這就是條件機率 (conditional probability),記作 \(P(A|B)\),讀作「在事件 \(B\) 發生的條件下,事件 \(A\) 發生的機率」:
\[P(A|B) = \frac{P(A \cap B)}{P(B)}\]
💡 教授的診間比喻: 假設全校有 10% 的人感冒(事件 \(A\)),有 20% 的人正在發燒(事件 \(B\)),而既感冒又發燒的人佔 8% (\(P(A \cap B) = 0.08\))。 今天有一位學生走進保健室,他已經在發燒了(已知 \(B\) 發生)。請問他得感冒的機率 \(P(A|B)\) 是多少? 答案是: \[P(A|B) = \frac{0.08}{0.20} = 0.40 \text{ (也就是 40\%)}\] 條件機率幫我們把關注的「宇宙範圍」從全校縮小到了「發燒的學生」這個小宇宙。
3.4 貝氏定理與醫學篩檢:診間的靈魂對話
當病人做了某項檢驗,報告呈現陽性時,病人和醫師最關心的問題通常是:「檢驗是陽性,我真的生病的機率是多少?」
要回答這個問題,我們必須使用統計學上最著名的定理之一——貝氏定理 (Bayes' Rule)。但在套用公式前,我們必須先認識醫學診斷篩檢 (screening test) 的五大核心指標。
3.4.1 篩檢的五大金剛
我們通常會拿篩檢試驗的結果,跟公認最準確的黃金標準 (gold standard, 例如切片病理報告、PCR 檢測) 進行對比,並畫出一個 \(2 \times 2\) 的表格:
| 篩檢結果 真實患病狀態 | 有病 (Disease +) | 無病 (Disease -) | 總計 |
|---|---|---|---|
| 陽性 (Test +) | 真陽性 (True Positive, TP) | 偽陽性 (False Positive, FP) | 所有陽性 |
| 陰性 (Test -) | 偽陰性 (False Negative, FN) | 真陰性 (True Negative, TN) | 所有陰性 |
| 總計 | 所有病人 | 所有健康者 | 總人數 |
盛行率 (Prevalence):在目標族群中,真正有病的人所佔的比例: \[P(D^+) = \frac{TP + FN}{\text{總人數}}\]
敏感度 (Sensitivity, Sn):在有病的人當中,篩檢成功驗出陽性的機率: \[Sn = P(T^+ | D^+) = \frac{TP}{TP + FN}\]
特異度 (Specificity, Sp):在沒病的人當中,篩檢正確給出陰性的機率: \[Sp = P(T^- | D^-) = \frac{TN}{TN + FP}\]
陽性預測值 (Positive Predictive Value, PPV):在篩檢為陽性的人當中,真正有病的機率: \[PPV = P(D^+ | T^+) = \frac{TP}{TP + FP}\]
陰性預測值 (Negative Predictive Value, NPV):在篩檢為陰性的人當中,真正沒病的機率: \[NPV = P(D^- | T^-) = \frac{TN}{TN + FN}\]
3.4.2 貝氏定理的魔法
如果我們已知某疾病在社區的盛行率 \(P(D^+)\),以及該篩檢試驗的敏感度 (\(Sn\)) 與特異度 (\(Sp\)),我們就可以利用貝氏定理算出陽性預測值 (PPV):
\[PPV = \frac{P(T^+ | D^+) P(D^+)}{P(T^+ | D^+) P(D^+) + P(T^+ | D^-) P(D^-)}\] \[PPV = \frac{Sn \times P(D^+)}{Sn \times P(D^+) + (1 - Sp) \times (1 - P(D^+))}\]
⚠️ 震撼臨床的例子: 假設某種罕見癌症的盛行率只有 0.1% (\(P(D^+) = 0.001\))。 有一家科技公司開發了超精準的檢測晶片,敏感度高達 99% (\(Sn = 0.99\)),特異度也高達 99% (\(Sp = 0.99\))。 今天你做了檢測,結果不幸是陽性。請問你真正得癌症的機率是多少? 同學們,直覺通常會告訴你「99% 完蛋了」。但讓我們用貝氏定理算算看: \[PPV = \frac{0.99 \times 0.001}{0.99 \times 0.001 + (1 - 0.99) \times (1 - 0.001)}\] \[PPV = \frac{0.00099}{0.00099 + 0.01 \times 0.999} = \frac{0.00099}{0.00099 + 0.00999} \approx 0.0901 \text{ (9\%!)}\]
沒錯!即使檢驗結果是陽性,你其實只有 9% 的機率真的得病,剩下的 91% 都是嚇死人的偽陽性! 為什麼? 因為在盛行率極低的情況下,健康的人佔了絕大多數(99.9%)。哪怕這群健康的人中只有 1% 會被偽報成陽性,這部分偽陽性的人數(0.00999)也遠遠超過了真正得病且被驗出陽性的人數(0.00099)。這就是為什麼醫學上不建議對健康大眾進行罕見疾病的大規模篩檢!
3.5 診斷評估利器:ROC 曲線與 AUC
在臨床實務上,許多檢驗指標並非單純的「陽性/陰性」,而是像「膽固醇濃度」或「發炎指標 (CRP)」這樣的連續型數值。我們必須人為設定一個切點 (cutoff point),大於此切點判為陽性,小於則為陰性。
- 如果切點設得很低,我們會驗出所有病人(高敏感度),但也會誤判許多健康人(低特異度)。
- 如果切點設得很高等,我們會非常確定驗出來的一定是病人(高特異度),但會漏掉很多病人(低敏感度)。
為了解決這個兩難,我們繪製 ROC 曲線 (receiver operating characteristic curve,接收者操作特徵曲線)。
- X 軸:偽陽性率 (\(1 - Specificity\))
- Y 軸:真陽性率 (\(Sensitivity\))
- AUC (Area Under the Curve, 曲線下面積):整個 ROC 曲線下方的面積。
- \(AUC = 0.5\):代表該檢驗指標毫無診斷價值,跟丟硬幣猜測一樣差(圖中對角虛線)。
- \(0.7 \le AUC < 0.8\):診斷效果一般。
- \(0.8 \le AUC < 0.9\):診斷效果良好。
- \(AUC \ge 0.9\):診斷效果極佳!
3.6 實戰演練:流感快速篩檢的 ROC 曲線繪製
現在,讓我們打開 RStudio,針對 100 位疑似流感患者的某發炎生物標記 (biomarker) 進行分析,計算出其敏感度、特異度,並繪製 ROC 曲線與計算 AUC。
3.6.1 RStudio 操作說明
- 開啟 RStudio。
- 開啟新的 R Script。
- 貼入以下程式碼並執行。本範例不依賴外部 package,全部使用純 R 邏輯與
ggplot2繪製,有助於你理解 ROC 曲線背後的數學計算!
3.6.2 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 模擬生成 100 位患者的數據 (50位患流感 Status=1, 50位健康 Status=0)
set.seed(42)
neg_biomarker <- rnorm(50, mean = 2, sd = 1) # 未患病者的標記濃度
pos_biomarker <- rnorm(50, mean = 3.5, sd = 1.2) # 患病者的標記濃度
flu_data <- data.frame(
Status = c(rep(0, 50), rep(1, 50)),
Biomarker = c(neg_biomarker, pos_biomarker)
)
# 3. 自訂函數:計算不同切點下的 TPR (Sensitivity) 與 FPR (1 - Specificity)
calculate_roc <- function(response, predictor) {
thresholds <- sort(unique(predictor))
roc_points <- data.frame(Threshold = thresholds, TPR = 0, FPR = 0)
total_pos <- sum(response == 1)
total_neg <- sum(response == 0)
for(i in seq_along(thresholds)) {
cutoff <- thresholds[i]
predicted_pos <- predictor >= cutoff
tp <- sum(predicted_pos & response == 1)
fp <- sum(predicted_pos & response == 0)
roc_points$TPR[i] <- tp / total_pos # 敏感度
roc_points$FPR[i] <- fp / total_neg # 1 - 特異度
}
# 加入邊界值以使曲線完整 (從 0,0 到 1,1)
roc_points <- rbind(data.frame(Threshold = Inf, TPR = 0, FPR = 0), roc_points)
roc_points <- rbind(roc_points, data.frame(Threshold = -Inf, TPR = 1, FPR = 1))
roc_points <- roc_points[order(roc_points$FPR, roc_points$TPR), ]
return(roc_points)
}
# 執行計算得到 ROC 座標
roc_df <- calculate_roc(flu_data$Status, flu_data$Biomarker)
# 4. 自訂函數:使用梯形法計算 AUC 面積
calculate_auc <- function(roc_data) {
df_sorted <- roc_data[order(roc_data$FPR), ]
n <- nrow(df_sorted)
auc <- 0
for(i in 1:(n-1)) {
# 梯形面積公式:(上底 + 下底) * 高 / 2
auc <- auc + (df_sorted$FPR[i+1] - df_sorted$FPR[i]) * (df_sorted$TPR[i] + df_sorted$TPR[i+1]) / 2
}
return(auc)
}
auc_val <- calculate_auc(roc_df)
# 5. 輸出 AUC 計算結果到控制台
cat("--- 診斷篩檢分析結果 ---\n")
cat("AUC 曲線下面積:", round(auc_val, 4), "\n")
cat("------------------------\n")
# 6. 使用 ggplot2 繪製 ROC 曲線並存檔
p_roc <- ggplot(roc_df, aes(x = FPR, y = TPR)) +
geom_path(color = "#3182ce", linewidth = 1.2) +
geom_abline(intercept = 0, slope = 1, linetype = "dashed", color = "#718096") +
annotate("text", x = 0.6, y = 0.3, label = paste("AUC =", round(auc_val, 3)),
size = 6.8, color = "#2d3748", family = "Noto Sans CJK TC") +
labs(
title = "流感快速篩檢試驗之 ROC 曲線",
subtitle = "呈現敏感度與一減特異度之關係",
x = "偽陽性率 False Positive Rate (1 - Specificity)",
y = "真陽性率 True Positive Rate (Sensitivity)"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
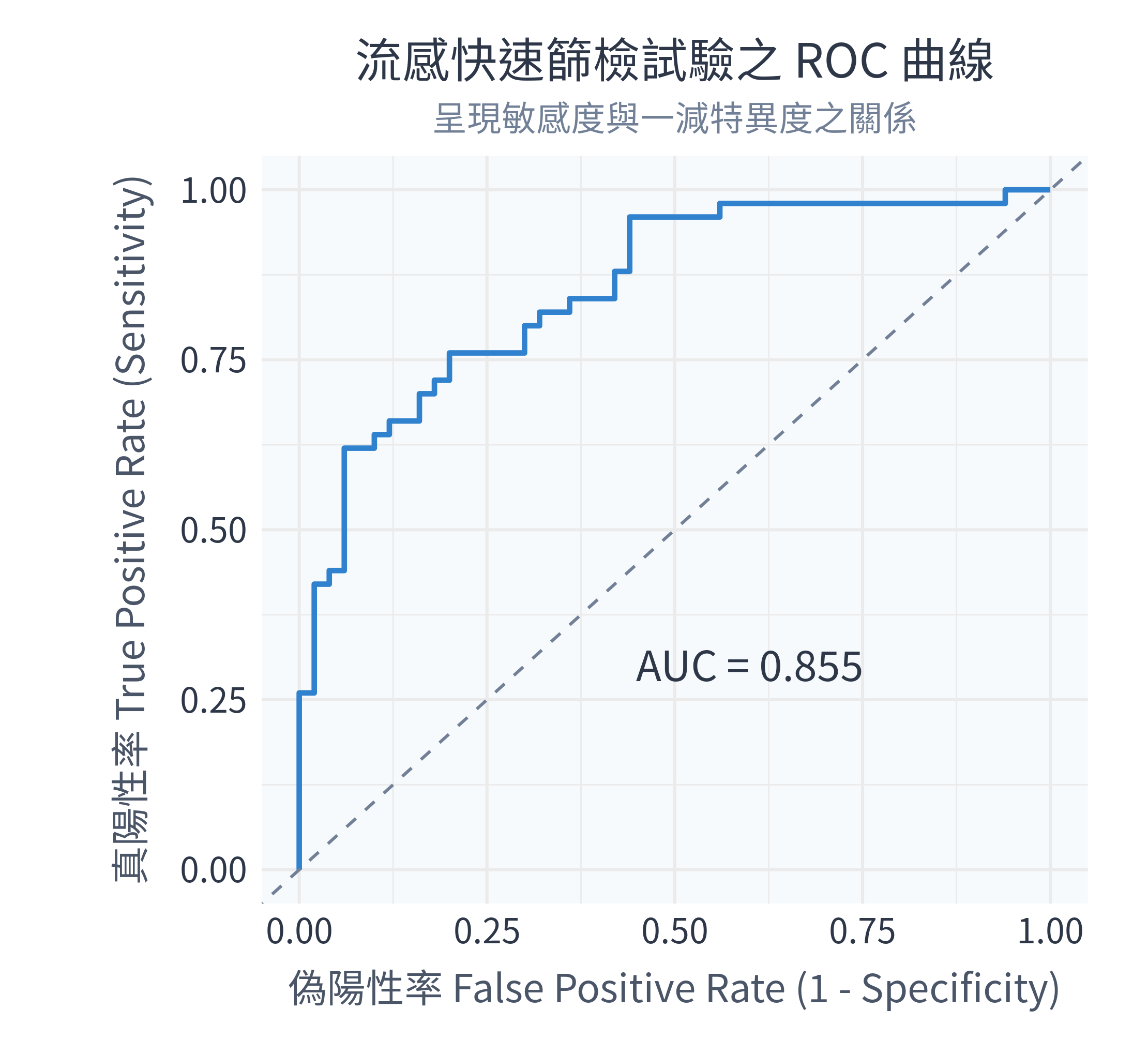
ggsave("figs/roc_curve.png", plot = p_roc, width = 7.4, height = 6.8, dpi = 300)3.6.3 執行結果與圖表解讀
在 R 中執行程式後,控制台會輸出:
--- 診斷篩檢分析結果 ---
AUC 曲線下面積: 0.8552
------------------------同時,figs/ 資料夾下會生成以下圖表:
數據診斷分析:
- AUC 解讀:這項流感生物標記檢測的 \(AUC\) 為 0.8552。這代表此標記在區分「患有流感者」與「健康者」的能力上達到了良好的標準。
- 臨床切點選擇:曲線左上角最靠近 (0,1) 的點,通常代表敏感度與特異度加總最大的位置,這也是臨床上常用來作為流感診斷的最佳切點。
3.7 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 機率 | Probability | 一個隨機事件發生可能性大小的數值度量 (0 到 1)。 |
| 樣本空間 | Sample space | 一個隨機試驗所有可能發生結果的完整集合。 |
| 事件 | Event | 樣本空間的子集,代表一個或多個試驗的結果。 |
| 互斥事件 | Mutually exclusive events | 不能在同一次試驗中同時發生的兩個事件。 |
| 獨立事件 | Independent events | 一個事件是否發生完全不影響另一個事件發生機率的兩個事件。 |
| 條件機率 | Conditional probability | 在已知某事件發生的前提下,另一事件發生的機率。 |
| 黃金標準 | Gold standard | 醫學上用來確診患者是否患有某疾病的最權威、最準確檢驗方法。 |
| 敏感度 | Sensitivity | 有病者當中被篩檢試驗正確判斷為陽性的機率(真陽性率)。 |
| 特異度 | Specificity | 沒病者當中被篩檢試驗正確判斷為陰性的機率(真陰性率)。 |
| 陽性預測值 | Positive predictive value (PPV) | 篩檢陽性者當中真正患有該疾病的機率。 |
| 陰性預測值 | Negative predictive value (NPV) | 篩檢陰性者當中真正沒有患該疾病的機率。 |
| 盛行率 | Prevalence | 某一特定時間點,目標族群中患有某疾病者的比例。 |
| 貝氏定理 | Bayes' rule / Bayes' theorem | 利用已知條件機率來更新或推算未知反向條件機率的數學公式。 |
| ROC 曲線 | ROC curve | 以真陽性率為 Y 軸,偽陽性率為 X 軸,呈現不同診斷切點下篩檢效能的曲線。 |
| 曲線下面積 | Area under the curve (AUC) | ROC 曲線下方的面積數值 (0.5 到 1.0),數值愈大代表診斷效能愈好。 |