第九章:無母數方法 (Nonparametric Methods)
9.1 導言:當常態假設崩潰時
同學們,在前兩章中,不論我們是做單樣本還是雙樣本的 t 檢定,背後都有一個默默支持我們的靈魂假設——常態假設 (normality assumption)。也就是說,我們默認我們的連續型數據(如體溫、血壓)在母體中是服從常態分布的。
但是,現實的臨床世界往往非常殘酷:
- 樣本數太小:很多罕見病研究,受試者只有 10 個人,你根本無法驗證數據是不是常態分布。
- 數據嚴重偏態或有極端離群值:例如患者的住院天數、醫療花費,通常有少數人花費極高,直方圖右邊拉得長長的。
- 等級資料 (ordinal data):這在醫學與護理研究中最為常見!例如:
- 患者的疼痛指數(1-10 分,10 代表最痛)。
- 癌症的臨床分期(I, II, III, IV 期)。
- 問卷滿意度(非常不滿意、不滿意、普通、滿意、非常滿意)。 這些數據只有大小順序關係,不能進行「相加求平均」的數學運算(你不能說癌症二期加癌症四期除以二等於癌症三期!)。
當遇到這些情況時,傳統的 t 檢定(母數方法,parametric methods)就會失效。這時,我們需要無母數方法 (nonparametric methods,又稱非參數方法)。
無母數方法是不受特定機率分布限制的(distribution-free),它不需要假設母體是常態分布。它的核心邏輯非常簡單粗暴:「把原始數值丟掉,只留下它們的『符號』或『大小排名 (Rank)』!」
9.2 符號檢定:只問成敗,不問細節
符號檢定 (sign test) 是無母數方法中最簡單的一種,適用於配對設計。
9.2.1 符號檢定的核心邏輯
想像我們有 10 位關節炎患者,接受了一種新的止痛貼片。我們記錄他們貼片「後」相較於貼片「前」的疼痛變化:
如果疼痛減輕了,我們記為「正號(+)」。
如果疼痛加劇了,我們記為「負號(-)」。
如果沒有變化,我們排除不計。
虛無假設 \(H_0\):貼片完全沒有效果。這意味著疼痛減輕(+)或加劇(-)的機率各為 50% (\(p = 0.5\))。
檢定方法:我們數一數總共有幾個正號。這其實就轉化成了一個非常簡單的二項分布 \(B(n, 0.5)\) 的機率計算!
符號檢定非常安全、好懂,但缺點是「浪費了太多資訊」。如果患者 A 疼痛分數降了 8 分,患者 B 只降了 1 分,在符號檢定中,他們都被記為一個簡單的「+」,這顯然有點委屈。
9.3 威爾科克森符號等級檢定:結合方向與程度的魔法
為了解決符號檢定浪費資訊的缺點,統計學家威爾科克森(Wilcoxon)設計了符號等級檢定 (Wilcoxon signed-rank test),適用於配對樣本。
9.3.1 計算四大步驟
- 計算差值:算出每對配對數據的差值 \(d_i = x_{1i} - x_{2i}\)。
- 排除零值並取絕對值:將差值為 0 的個案剃除。對剩下的差值取絕對值 \(|d_i|\)。
- 排序(Rank):將這些絕對值 \(|d_i|\) 從小到大進行排名,得到等級(Rank,數值越小排名越前面)。
- 同秩 (ties) 處理:如果有兩個或多個差值的絕對值相同,我們取它們排名的平均值作為它們的等級。
- 加總等級:
- 將原本差值為正數的等級加總,得到 \(T^+\)。
- 將原本差值為負數的等級加總,得到 \(T^-\)。
- 在虛無假設 \(H_0\)(沒有療效)為真的世界中,\(T^+\) 與 \(T^-\) 的大小應該要非常接近。如果其中一個遠大於另一個,就代表有顯著差異。
9.4 威爾科克森秩和檢定:獨立樣本的救星
當我們要比較兩組獨立的樣本,且數據不服從常態分布時,我們不能用獨立雙樣本 t 檢定。此時,我們使用威爾科克森秩和檢定 (Wilcoxon rank-sum test,在數學上與 Mann-Whitney U 檢定 等價)。
9.4.1 計算步驟
- 合併數據與排名:將兩組獨立的數據(組 1 有 \(n_1\) 人,組 2 有 \(n_2\) 人)合併在一起,從小到大進行總排名(Rank \(1\) 到 \(n_1 + n_2\))。同樣遇到數值相同者取平均排名。
- 分組求和:將排名還原給原本的組別,分別加總兩組的等級和,得到 \(W_1\) 與 \(W_2\)。
- 檢定決策:在虛無假設為真(兩組分佈無差異)時,兩組平均的排名應當差不多。利用統計公式,我們可以算得 \(W_1\) 的 p 值,據此決定是否拒絕虛無假設。
9.5 實戰演練:穴位按壓療法之疼痛評分比較
現在,我們打開 RStudio。我們設計了以下疼痛研究:
- 配對分析:12 位關節炎患者,評估其接受穴位按壓治療「前 (Before)」與「後 (After)」的疼痛感(使用 1-10 疼痛量尺,Ordinal scale)。我們使用 Wilcoxon 符號等級檢定。
- 獨立樣本分析:另外 12 位患者接受了虛假的假按壓作為「對照組 (Control)」,評估其治療後的疼痛感,並與穴位按壓組治療後的疼痛感進行比較。我們使用 Wilcoxon 秩和檢定。
9.5.1 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 模擬生成疼痛等級數據 (1 到 10 分)
set.seed(88)
pain_before <- c(8, 7, 9, 6, 8, 10, 7, 9, 8, 6, 9, 8)
# 穴位按壓組治療後 (疼痛分數下降)
pain_after <- c(4, 3, 5, 4, 3, 6, 5, 4, 5, 2, 4, 5)
# 對照組 (假按壓治療後,疼痛分數降幅較小)
pain_control <- c(7, 6, 8, 5, 7, 9, 6, 8, 7, 5, 8, 6)
# =======================================================
# 實作一:配對 Wilcoxon 符號等級檢定 (穴位按壓組前後比較)
# =======================================================
wilcox_paired_res <- wilcox.test(pain_before, pain_after, paired = TRUE)
# =======================================================
# 實作二:獨立樣本 Wilcoxon 秩和檢定 (按壓組後 vs. 對照組後)
# =======================================================
wilcox_ind_res <- wilcox.test(pain_after, pain_control, paired = FALSE)
# 輸出結果
cat("=========================================\n")
cat(" 實作一:Wilcoxon 符號等級檢定結果 (配對)\n")
cat("=========================================\n")
print(wilcox_paired_res)
cat("\n=========================================\n")
cat(" 實作二:Wilcoxon 秩和檢定結果 (獨立雙樣本)\n")
cat("=========================================\n")
print(wilcox_ind_res)
# =======================================================
# 3. 資料整理與 ggplot2 小提琴圖 (Violin Plot) 繪製
# =======================================================
plot_df <- data.frame(
Group = factor(c(rep("穴位按壓組 (Acupressure)", 24), rep("對照組 (Control)", 12)),
levels = c("對照組 (Control)", "穴位按壓組 (Acupressure)")),
Time = factor(c(rep("治療前 (Before)", 12), rep("治療後 (After)", 12), rep("治療後 (After)", 12)),
levels = c("治療前 (Before)", "治療後 (After)")),
PainScore = c(pain_before, pain_after, pain_control)
)
p_violin <- ggplot(plot_df, aes(x = Group, y = PainScore, fill = Time)) +
# 繪製小提琴圖
geom_violin(trim = FALSE, alpha = 0.7, color = "#2d3748", position = position_dodge(0.8)) +
# 重疊繪製個別患者的疼痛數據散佈點 (使用 jitter 避免重疊)
geom_jitter(shape = 16, position = position_dodge(0.8), color = "#1a202c", size = 2, alpha = 0.5) +
scale_fill_manual(values = c("治療前 (Before)" = "#feb2b2", "治療後 (After)" = "#e53e3e")) +
scale_y_continuous(limits = c(0, 11), breaks = 1:10) +
labs(
title = "穴位按壓與對照組之疼痛感評分比較",
subtitle = "呈現無母數等級資料 (1-10 疼痛量尺) 之分布與變異",
x = "受試組別 (Group)",
y = "疼痛評分 Pain Score (1-10)",
fill = "量測時間點"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
legend.title = element_text(size = 16, color = "#4a5568"),
legend.position = "bottom",
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 顯示並儲存圖檔
print(p_violin)
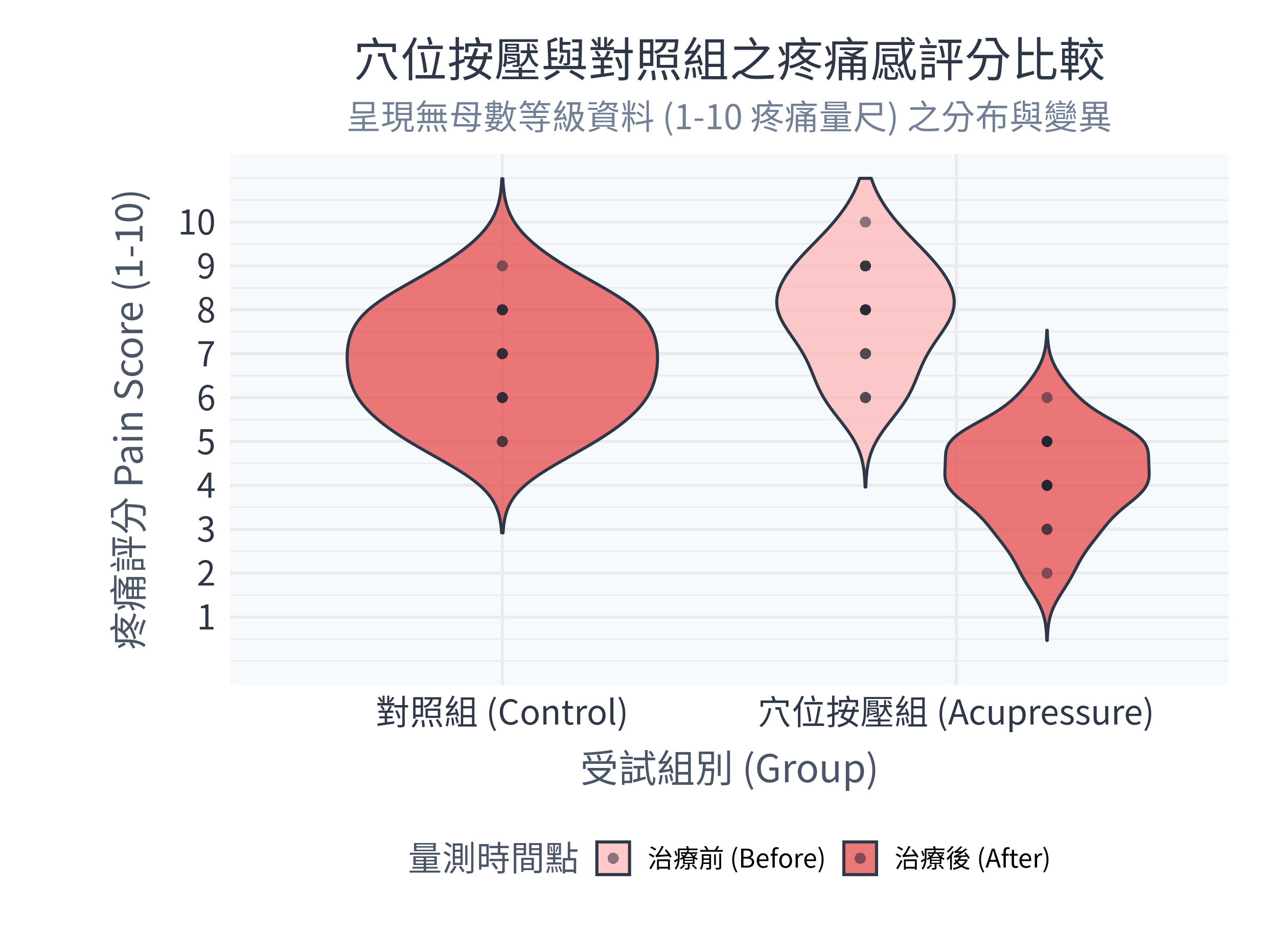
ggsave("figs/pain_comparison.png", plot = p_violin, width = 8.4, height = 6.1, dpi = 300)9.5.2 執行結果與圖表解讀
在 R 中執行程式後,控制台主要輸出:
Wilcoxon 符號等級檢定(相依):
V = 78, p-value = 0.002282。 這代表穴位按壓組在治療前後的疼痛指數有極其顯著的改善 (\(p = 0.002 < 0.05\))。Wilcoxon 秩和檢定(獨立):
W = 3.5, p-value = 0.0001786。 治療後,穴位按壓組的疼痛程度顯著低於對照組 (\(p < 0.001\))。
同時,figs/ 資料夾下會生成以下圖表:
數據診斷分析與決策:
- 本範例使用小提琴圖 (violin plot) 來視覺化疼痛評分的分佈。小提琴圖的外側寬度代表數據在該分數的機率密度。
- 從圖中可以看出,按壓組(右側)在治療前(粉紅色小提琴),病患疼痛感集中在 8 分的高位;而在治療後(紅色小提琴),分佈明顯下移,集中在 3-5 分的區間。
- 相比之下,對照組在治療後(紅色小提琴),疼痛分數大多維持在 6-8 分的相對高位。這與我們的無母數假設檢定結果完全一致,證明了穴位按壓療法的顯著臨床療效。
9.6 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 無母數方法 | Nonparametric methods | 不依賴母體特定機率分布假設(如常態分布)的統計推論方法。 |
| 等級資料 (順序資料) | Ordinal data | 數據只有大小順序意義,但數值間的差值無精確數學度量的資料類型。 |
| 符號檢定 | Sign test | 最簡單的無母數檢定,僅利用配對差值的正負符號方向來進行假設檢定。 |
| 符號等級檢定 | Wilcoxon signed-rank test | 對配對樣本差值絕對值進行大小排名,並加總正負等級以檢定療效的方法。 |
| 秩和檢定 | Wilcoxon rank-sum test | 將兩組獨立樣本合併排名,加總某一組的等級和,用以檢定兩組分佈是否相同的無母數方法。 |
| 同秩 | Ties | 當不同個案的觀測數值相同,導致其排名(Rank)並列相同的狀況。 |
| 小提琴圖 | Violin plot | 結合了箱形圖與核密度估計,能同時展示數據分佈形狀與機率密度的統計圖表。 |
| 等級 / 秩 | Rank | 數據從小到大排序後所獲得的序數名次。 |
| 偏態分布 | Skewed distribution | 數據分布不對稱,尾巴偏向某一側的機率分布。 |