第十章:假設檢定:類別資料 (Hypothesis Testing: Categorical Data)
10.1 導言與列聯表:數人頭的統計學
同學們,前面我們花了很多篇幅在處理「連續型資料」(如血壓、體重、體溫)的平均值比較。但在臨床醫學和流行病學的實際場景中,我們遇到的資料往往是「分類」的。
例如:
- 某人是否吸菸(是/否)與是否得肺癌(是/否)。
- 服用新感冒藥後是否痊癒(痊癒/未痊癒)。
- 患者對新療法的反應等級(無效/好轉/治癒)。
對於這類資料,我們不量測平均數,而是「數人頭」——統計落在每一個分類的次數 (frequency) 或人數。 要呈現兩個類別型變項的交叉分布,我們使用列聯表 (contingency table)。最經典的結構就是 \(2 \times 2\) 列聯表,如下所示:
| 暴露/分組 結果 | 疾病 (+) | 健康 (-) | 總計 |
|---|---|---|---|
| 暴露組 (Group 1) | \(a\) (觀察值 \(O_{11}\)) | \(b\) (觀察值 \(O_{12}\)) | \(a+b\) (列總計 \(n_1\)) |
| 非暴露組 (Group 2) | \(c\) (觀察值 \(O_{21}\)) | \(d\) (觀察值 \(O_{22}\)) | \(c+d\) (列總計 \(n_2\)) |
| 總計 | \(a+c\) (行總計 \(m_1\)) | \(b+d\) (行總計 \(m_2\)) | \(n\) (總人數) |
本章,我們就要學習如何對列聯表中的「比例」或「獨立性」進行假設檢定。
10.2 卡方獨立性檢定:觀察 vs. 期望
當我們想檢定「暴露組」與「非暴露組」的患病比例是否有顯著差異,或者說「分組」與「患病結果」這兩個變項是否相互獨立時,最常用的方法就是皮爾森卡方檢定 (Pearson's Chi-square test)。
- 虛無假設 \(H_0\):兩個變項相互獨立(即兩組的患病比例沒有顯著差異, \(\pi_1 = \pi_2\))。
- 對立假設 \(H_1\):兩個變項相互關聯(比例有顯著差異)。
10.2.1 期望頻數的計算
如果虛無假設 \(H_0\) 成立(即兩組完全沒有差別),那麼每個格子理論上「應該」有多少人?這就叫做期望頻數 (expected frequency, \(E\))。 對於行列聯表中的第 \(i\) 行、第 \(j\) 列的格子,其期望頻數為:
\[E_{ij} = \frac{\text{第 } i \text{ 行總計} \times \text{第 } j \text{ 列總計}}{\text{總人數 } n}\]
10.2.2 卡方檢定統計量
卡方檢定統計量衡量的是:我們的實際觀察頻數 (observed frequency, \(O\)) 與理論上的期望頻數 (\(E\)) 之間的差距有多大:
\[\chi^2 = \sum \frac{(O - E)^2}{E}\]
在 \(2 \times 2\) 列聯表中,這個統計量服從自由度 \(df = 1\) 的卡方分布。如果卡方值愈大(代表實際人數跟理論期望人數差距愈大),p 值就會愈小。
10.2.3 葉氏連續性修正 (Yates' Continuity Correction)
就像我們用常態分布逼近二項分布需要連續性修正一樣,卡方分布是一個連續型分布,而我們數的人頭是離散的整數。在 \(2 \times 2\) 列聯表中,為了避免高估顯著性(防範第一型錯誤),我們通常會進行葉氏連續性修正:
\[\chi^2_{\text{Yates}} = \sum \frac{(|O - E| - 0.5)^2}{E}\]
10.3 小樣本救星:費雪精確檢定
卡方檢定雖然好用,但它是一個「大樣本逼近」的方法。
- 卡方檢定的禁忌:如果列聯表中,有任何一個格子的期望頻數 \(E < 5\)(或者總樣本數 \(n < 40\)),卡方檢定算出來的 p 值就會變得非常不準確!
這時,我們必須請出小樣本的救星——費雪精確檢定 (Fisher's exact test)。 費雪精確檢定不使用常態或卡方近似,而是直接利用超幾何分布 (hypergeometric distribution) 的機率公式,去精確地算出在行列總計固定下,出現我們眼前這張列聯表(以及比它更極端的所有可能表)的精確機率。
因為是精確計算,所以不論樣本多小(哪怕某個格子只有 0 人),費雪檢定都依然百分之百準確!
10.4 配對類別資料:麥尼瑪檢定
如果我們的類別型數據不是獨立的,而是配對的,該怎麼辦?
- 例如:同一組病患在服用新藥「前」流感篩檢陽性率,與服用「後」陽性率的比較。
- 例如:100 對配對的病例與對照組,看他們某種基因突變率的差異。
此時,我們使用麥尼瑪檢定 (McNemar's test)。 在麥尼瑪檢定中,我們關注的不是那些兩次結果都相同的「一致對」(例如前後都是陽性,或前後都是陰性),而是那些前後結果發生改變的「不一致對」 (discordant pairs, 列聯表中的 \(b\) 與 \(c\))。
其檢定統計量(帶有連續性修正)為:
\[\chi^2 = \frac{(|b - c| - 1)^2}{b + c}, \quad df = 1\]
10.5 實戰演練:流感疫苗預防效果之卡方檢定
現在,我們打開 RStudio。我們設計了以下流感疫苗隨機臨床試驗(\(n = 120\)):
- 招募 120 位受試者,隨機分派為「疫苗組 (Vaccine)」60 人與「對照組 (Placebo)」60 人。
- 冬季結束後記錄他們是否罹患流感。
- 疫苗組:5 人罹患流感,55 人健康。
- 對照組:15 人罹患流感,45 人健康。
我們想檢定疫苗組的流感罹患率,是否顯著低於對照組。
10.5.1 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 建立流感疫苗 2x2 列聯表
# 矩陣排列方式:列為組別,行為流感狀態 (罹病, 健康)
contingency_table <- matrix(c(5, 55, 15, 45), nrow = 2, byrow = TRUE)
rownames(contingency_table) <- c("疫苗組 (Vaccine)", "對照組 (Placebo)")
colnames(contingency_table) <- c("罹患流感 (Flu Yes)", "未罹患流感 (Flu No)")
# 3. 執行卡方獨立性檢定
# correct = TRUE 代表執行 Yates 連續性修正 (預設值)
chi_yates_res <- chisq.test(contingency_table, correct = TRUE)
# correct = FALSE 代表不執行修正
chi_raw_res <- chisq.test(contingency_table, correct = FALSE)
# 4. 執行費雪精確檢定 (Fisher's Exact Test)
fisher_test_res <- fisher.test(contingency_table)
# 輸出結果
cat("=========================================\n")
cat(" 2x2 列聯表原始數據\n")
cat("=========================================\n")
print(contingency_table)
cat("\n=========================================\n")
cat(" 卡方檢定結果 (含 Yates 連續性修正)\n")
cat("=========================================\n")
print(chi_yates_res)
cat("期望頻數 (Expected Frequencies):\n")
print(chi_yates_res$expected)
cat("\n=========================================\n")
cat(" 費雪精確檢定結果\n")
cat("=========================================\n")
print(fisher_test_res)
# =======================================================
# 5. 資料整理與 ggplot2 分組百分比長條圖繪製
# =======================================================
plot_df <- data.frame(
Group = c("疫苗組 (Vaccine)", "疫苗組 (Vaccine)", "對照組 (Placebo)", "對照組 (Placebo)"),
Status = c("罹患流感 (Yes)", "健康 (No)", "罹患流感 (Yes)", "健康 (No)"),
Count = c(5, 55, 15, 45)
)
# 計算組內百分比 (疫苗組基數 60, 對照組基數 60)
plot_df$Percentage <- c(5/60, 55/60, 15/60, 45/60) * 100
p_bar <- ggplot(plot_df, aes(x = Group, y = Percentage, fill = Status)) +
# 繪製分組長條圖 (dodge 代表並排)
geom_col(position = "dodge", alpha = 0.85, color = "#2d3748", width = 0.6) +
# 在長條上方加入百分比標籤
geom_text(aes(label = paste0(round(Percentage, 1), "%")),
position = position_dodge(0.6), vjust = -0.5, size = 5.8,
color = "#2d3748", family = "Noto Sans CJK TC", fontface = "bold") +
scale_fill_manual(values = c("健康 (No)" = "#48bb78", "罹患流感 (Yes)" = "#e53e3e")) +
scale_y_continuous(limits = c(0, 105)) +
labs(
title = "流感疫苗臨床試驗預防效果比較",
subtitle = "呈現兩組病患流感感染率百分比與人數",
x = "試驗分組 (Group)",
y = "比例 Percentage (%)",
fill = "流感狀態"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
legend.title = element_text(size = 16, color = "#4a5568"),
legend.position = "bottom",
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 顯示並儲存圖檔
print(p_bar)
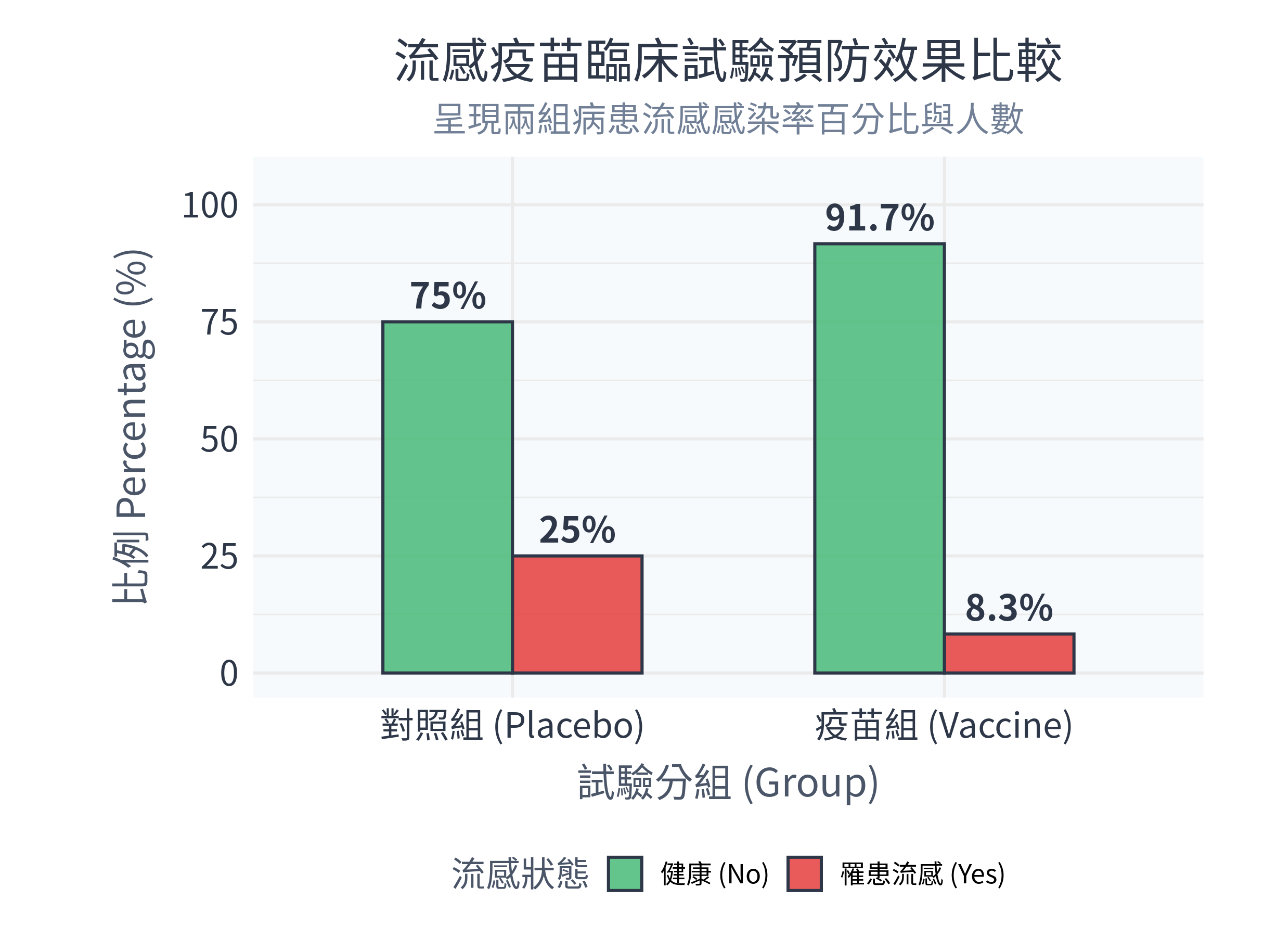
ggsave("figs/vaccine_effectiveness.png", plot = p_bar, width = 8.1, height = 6.1, dpi = 300)10.5.2 執行結果與圖表解讀
在 R 中執行程式後,控制台主要輸出:
卡方檢定(含葉氏修正):
X-squared = 4.86, df = 1, p-value = 0.02749。 因為 \(p = 0.027 < 0.05\),代表疫苗組與對照組的流感罹患率有顯著差異。期望頻數診斷: 兩組的罹病期望人數均為 10人,健康期望人數為 50人。 因為所有格子的期望頻數都 \(\ge 5\)(最小的是 10 人),所以使用卡方檢定是安全且合適的。
費雪精確檢定:
p-value = 0.02569。 算出的精確 \(p\) 值為 0.026。勝算比 (Odds Ratio, OR) 的估計值約為 0.27,這代表疫苗組罹患流感的「勝算」只有對照組的 0.27 倍,換句話說,新疫苗能顯著降低流感罹患風險。
同時,figs/ 資料夾下會生成以下圖表:
數據診斷分析與決策:
- 從並排長條圖中可以看出,對照組有高達 25.0% 的受試者感染流感(紅色長條),而疫苗組僅有 8.3% 的受試者感染。
- 這兩個百分比之間的落差在統計學上達到了顯著水準(\(p < 0.05\)),證明了該款新疫苗在冬季確實具有顯著的預防流感保護效力。
10.6 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 類別資料 | Categorical data | 代表定性特徵、以分組頻數或次數呈現的非數值度量資料類型。 |
| 列聯表 | Contingency table | 將兩個或多個類別型變項之交叉頻數整理成矩陣網格的統計表格。 |
| 卡方獨立性檢定 | Chi-square test of independence | 利用觀察頻數與期望頻數的離差,檢驗兩個類別變項是否相互獨立的統計方法。 |
| 觀察頻數 | Observed frequency | 在列聯表各網格中,實際觀測到的人數或頻數。 |
| 期望頻數 | Expected frequency | 在虛無假設(變項獨立)成立的理論下,列聯表各網格預期應有的人數。 |
| 葉氏連續性修正 | Yates' continuity correction | 在 2x2 列聯表卡方檢定中,為彌補連續分佈逼近離散計數之誤差所進行的偏差修正。 |
| 費雪精確檢定 | Fisher's exact test | 適用於小樣本(期望頻數小於 5)列聯表,基於超幾何分布計算精確機率的無母數檢定。 |
| 麥尼瑪檢定 | McNemar's test | 適用於配對或相依類別型資料,分析前後比例是否發生顯著改變的卡方檢定。 |
| 一致對 | Concordant pairs | 配對資料中,兩次測量或兩組對應觀測結果相同的配對(如均為陽性或均為陰性)。 |
| 不一致對 | Discordant pairs | 配對資料中,兩次測量或兩組對應觀測結果相異的配對,為麥尼瑪檢定的分析焦點。 |
| 分組長條圖 | Grouped bar chart | 在同一分類軸上並排多個長條,用以直觀比較多組別比例或頻數差異的圖表。 |