第十一章:迴歸與相關方法 (Regression and Correlation Methods)
11.1 導言與變項關係:探索連續變項的羈絆
同學們,在前面的章節中,我們學會了如何比較兩組人的平均數(t 檢定)或比例(卡方檢定)。
但如果我們手上有兩個連續型變項,我們想知道它們之間是否有關聯,甚至想用其中一個來預測另一個,那該怎麼辦? 例如:
- 「患者的年齡(歲)與收縮壓(mmHg)之間是否有關係?年齡愈大,血壓愈高嗎?」
- 「孕婦的孕期體重增加量(kg)與新生兒的出生體重(g)有何關係?」
這就帶出了生物統計學中極為重要的兩大分析武器:相關分析 (correlation analysis) 與迴歸分析 (regression analysis)。
在進行分析前,我們必須先釐清兩個變項的角色:
- 自變項 / 預測變項 (Independent / Predictor Variable, 通常記為 \(X\)):代表原因,或者我們用來進行預測的基礎。例如「年齡」。
- 依變項 / 反應變項 (Dependent / Response Variable, 通常記為 \(Y\)):代表結果,即我們想要預測或解釋的臨床指標。例如「收縮壓」。
11.2 皮爾森相關係數:關係有多鐵?
當我們只想單純知道兩個連續變項之間,是否存在線性關係 (linear relationship) 以及關係的強度與方向時,我們使用皮爾森積差相關係數 (Pearson correlation coefficient,簡稱相關係數 \(r\))。
11.2.1 相關係數 \(r\) 的三大特徵
- 取值範圍: \(-1 \le r \le 1\)。
- 方向性:
- \(r > 0\) 代表正相關: \(X\) 增加時,\(Y\) 也趨向增加(例如:年齡與血壓)。
- \(r < 0\) 代表負相關: \(X\) 增加時,\(Y\) 反而減少(例如:運動時間與體脂肪率)。
- \(r = 0\) 代表無線性相關(不代表沒有其他非線性關係!)。
- 強度: \(|r|\) 愈接近 1,代表線性關係愈強:
- \(|r| \ge 0.7\):強烈相關。
- \(0.4 \le |r| < 0.7\):中度相關。
- \(|r| < 0.4\):弱相關。
11.2.2 相關係數的假設檢定
我們在樣本中算出的相關係數 \(r\),必須進行假設檢定,以確認在母體中這兩個變項是否真的存在關聯:
- 虛無假設 \(H_0: \rho = 0\) (母體相關係數為 0,即無關聯)。
- 對立假設 \(H_1: \rho \neq 0\)。
11.3 簡單線性迴歸:預測臨床的未來
如果相關分析告訴我們「關係很鐵」,那麼我們就可以更進一步,用一個自變項 \(X\) 來預測依變項 \(Y\)。這就是簡單線性迴歸 (simple linear regression)。
11.3.1 迴歸方程式
簡單線性迴歸的理論模型為:
\[Y = \beta_0 + \beta_1 X + e\]
而我們利用樣本數據擬合出來的迴歸直線公式為:
\[\hat{y} = b_0 + b_1 x\]
- 斜率 (\(b_1\)):這條直線最精華的部分!代表自變項 \(X\) 每增加一個單位時,依變項 \(Y\) 預期會增加(或減少)多少。
- 截距 (\(b_0\)):代表當自變項 \(X = 0\) 時,依變項 \(Y\) 的預測值。在醫學上, \(X=0\) 有時沒有實際物理意義(例如年齡為 0 歲的收縮壓),此時截距僅作為數學定位點。
11.3.2 最小平方法 (Method of Least Squares)
我們是怎麼決定這條「最合適」的直線的? 我們使用的是最小平方法。它的原理是計算每一個實際觀測點與這條直線之間的垂直距離(即殘差, residual),然後尋找一條直線,使得所有觀測點的殘差平方和 (Residual Sum of Squares, RSS) 達到最小。
11.4 迴歸模型的評估與診斷
建構完迴歸線後,我們需要回答兩個問題:
11.4.1 斜率是否顯著?
如果自變項 \(X\) 根本無法預測 \(Y\),那麼這條線應該是一條水平線(斜率 \(\beta_1 = 0\))。因此我們必須對斜率進行假設檢定:
- 虛無假設 \(H_0: \beta_1 = 0\) (自變項對依變項沒有預測力)。
- 對立假設 \(H_1: \beta_1 \neq 0\)。 我們可以利用 t 檢定或 F 檢定來求得 p 值。
11.4.2 模型解釋力有多強:判定係數 (\(R^2\))
判定係數 (coefficient of determination,記為 \(R^2\)) 是衡量迴歸模型好壞的關鍵指標。
\[R^2 = 1 - \frac{\text{殘差平方和 (RSS)}}{\text{總平方和 (TSS)}}\]
\(R^2\) 的數值介於 0 與 1 之間,代表依變項 \(Y\) 的總變異中,有多少比例可以被自變項 \(X\) 的迴歸模型所解釋。 例如,\(R^2 = 0.54\) 代表患者收縮壓中 54% 的變異是由於「年齡差異」引起的,剩下的 46% 變異則歸咎於其他未納入模型的臨床因素(如遺傳、飲食等)。
11.5 斯皮爾曼等級相關:無母數相關分析
如果我們的變項數據不符合常態分布,或是等級資料(如疼痛評分與焦慮等級),我們就不能計算皮爾森 \(r\)。此時,我們將數據排序後計算斯皮爾曼等級相關係數 (Spearman rank correlation coefficient, \(r_s\))。其原理與皮爾森相同,只是對象換成了排名。
11.6 實戰演練:年齡與收縮壓之線性迴歸分析
現在,我們打開 RStudio。我們收集了 15 位病患的年齡(Age,歲)與收縮壓(SBP,mmHg),我們要分析兩者間的相關性,建立線性迴歸模型,並繪製出包含 95% 信賴區間帶 (confidence band) 的精美散佈圖。
11.6.1 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 模擬生成 15 位受試者的年齡與收縮壓數據
set.seed(99)
age_vals <- c(25, 34, 45, 52, 60, 28, 38, 48, 55, 65, 30, 42, 50, 58, 67)
# 設定線性關係,加上隨機雜訊
sbp_vals <- 105 + 0.5 * age_vals + rnorm(15, mean = 0, sd = 4)
df_reg <- data.frame(Age = age_vals, SBP = sbp_vals)
# =======================================================
# 實作一:皮爾森相關分析
# =======================================================
cor_res <- cor.test(df_reg$Age, df_reg$SBP)
# =======================================================
# 實作二:簡單線性迴歸分析 (SBP ~ Age)
# =======================================================
# lm() 是 R 中建構線性模型 (linear model) 的核心函數
lm_model <- lm(SBP ~ Age, data = df_reg)
lm_summary <- summary(lm_model)
# 輸出統計結果
cat("=========================================\n")
cat(" 實作一:皮爾森相關分析結果\n")
cat("=========================================\n")
cat("相關係數 r :", round(cor_res$estimate, 4), "\n")
cat("95% 信賴區間 : [", round(cor_res$conf.int[1], 4), ",", round(cor_res$conf.int[2], 4), "]\n")
cat("相關性檢定 p 值 :", round(cor_res$p.value, 4), "\n\n")
cat("=========================================\n")
cat(" 實作二:簡單線性迴歸分析結果\n")
cat("=========================================\n")
print(lm_summary)
# =======================================================
# 3. 使用 ggplot2 繪製散佈圖與迴歸線及 95% 信賴區間帶
# =======================================================
p_reg <- ggplot(df_reg, aes(x = Age, y = SBP)) +
# 繪製病患原始散佈點
geom_point(size = 3.5, color = "#2c5282", alpha = 0.8) +
# geom_smooth() 配合 method="lm" 與 se=TRUE 會自動繪製迴歸線與半透明信賴區間帶
geom_smooth(method = "lm", se = TRUE, color = "#3182ce", fill = "#bee3f8", alpha = 0.5, linewidth = 1.2) +
labs(
title = "患者年齡與收縮壓之線性迴歸關係",
subtitle = paste0("相關係數 r = ", round(cor_res$estimate, 3),
", 判定係數 R² = ", round(lm_summary$r.squared, 3)),
x = "年齡 Age (years)",
y = "收縮壓 Systolic BP (mmHg)"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 顯示並儲存圖檔
print(p_reg)
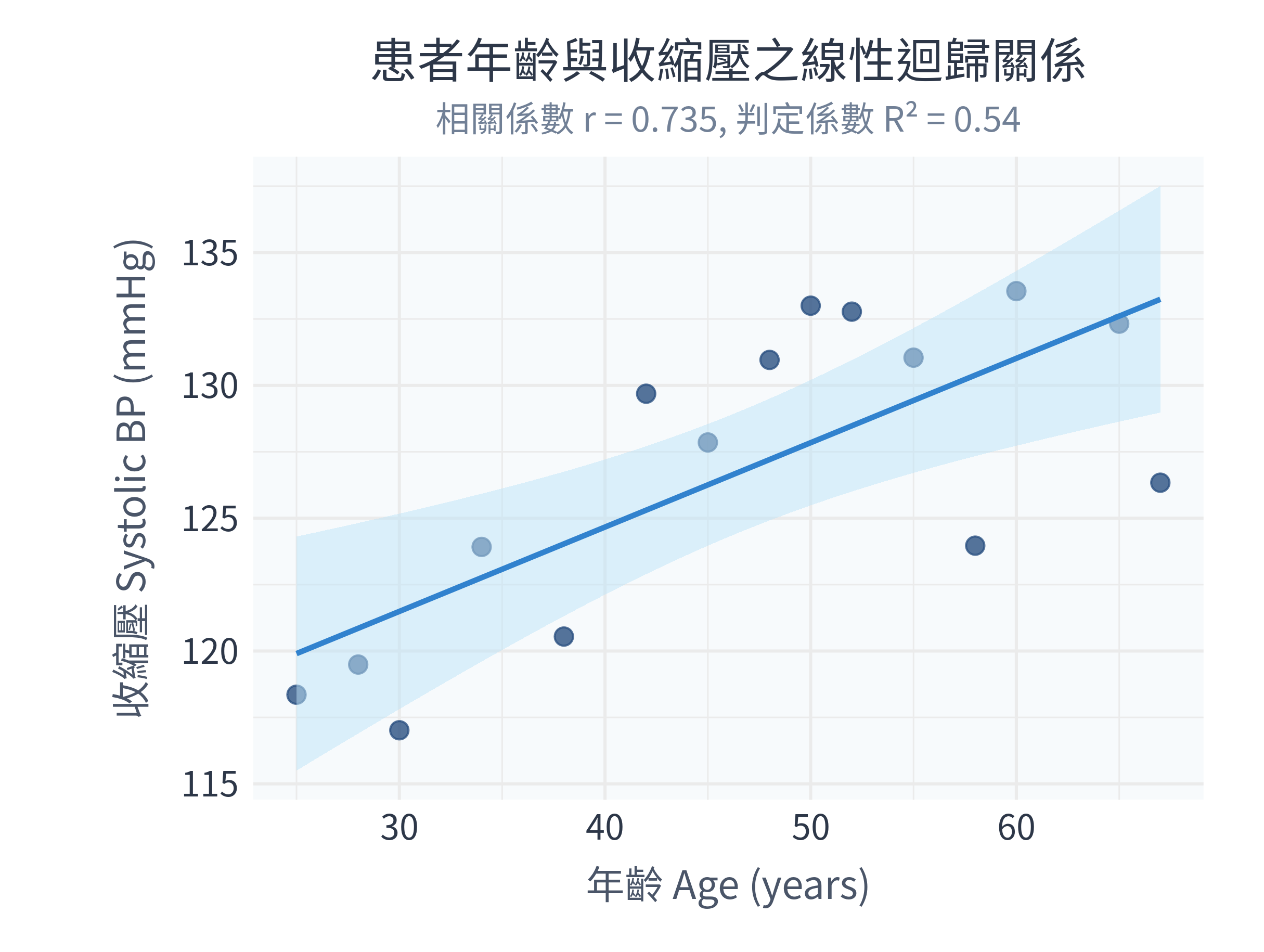
ggsave("figs/sbp_regression.png", plot = p_reg, width = 8.1, height = 6.1, dpi = 300)11.6.2 執行結果與圖表解讀
在 R 中執行程式後,控制台主要輸出:
相關分析: \(r = 0.7349\),\(p\)-value = 0.0018。 這代表年齡與收縮壓之間存在強烈的正相關,且達到高度統計學顯著性。
迴歸分析係數:
- 截距 (\(b_0\)):
111.96,代表理論上 0 歲時的收縮壓。 - 斜率 (\(b_1\)):
0.3176, \(p = 0.0018\)。 這代表年齡每增加 1 歲,收縮壓平均預期會顯著升高 0.32 mmHg!
- 截距 (\(b_0\)):
判定係數 (\(R^2\)):
Multiple R-squared: 0.54。 這代表我們的迴歸模型(年齡)能解釋收縮壓中 54% 的變異。
同時,figs/ 資料夾下會生成以下圖表:
數據診斷分析與決策:
- 在圖表中,實線代表我們的擬合迴歸線 \(\hat{y} = 111.96 + 0.32x\)。
- 環繞在藍色實線周圍的淺藍色半透明區塊就是 95% 信賴區間帶。信賴帶在中間(平均年齡附近)最窄,在兩端(年輕與高齡)最寬,這生動地呈現了線性迴歸在均值附近預測最精準、兩端誤差較大的數學特徵。
11.7 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 相關分析 | Correlation analysis | 探討兩個連續型隨機變項間是否存在線性關聯強度與方向的統計方法。 |
| 迴歸分析 | Regression analysis | 建立自變項與依變項間之數學方程式,用以進行預測與因果探索的統計方法。 |
| 自變項 (預測變項) | Independent variable (X) | 在迴歸模型中,用來預測或解釋依變項變化的輸入變項。 |
| 依變項 (反應變項) | Dependent variable (Y) | 迴歸模型中,研究者關注並希望進行預測的輸出結果變項。 |
| 皮爾森相關係數 | Pearson correlation coefficient (r) | 衡量兩個連續型變項線性關聯強度與方向的數值指標 (-1 到 1)。 |
| 簡單線性迴歸 | Simple linear regression | 僅包含一個自變項與一個依變項之線性關係的迴歸模型。 |
| 最小平方法 | Method of least squares | 通過使所有數據點到迴歸線之殘差平方和最小化,來擬合最佳直線的方法。 |
| 斜率 | Slope (\(b_1\)) | 迴歸線的傾斜度,代表自變項每變動一單位時,依變項預期的平均變動量。 |
| 截距 | Intercept (\(b_0\)) | 迴歸線與 Y 軸相交之點,代表當自變項為 0 時,依變項的預測值。 |
| 判定係數 | Coefficient of determination (\(R^2\)) | 衡量迴歸模型解釋力大小的指標,代表依變項總變異能被模型解釋的比例。 |
| 斯皮爾曼等級相關 | Spearman rank correlation | 基於數據等級排名(Rank)計算相關性,適用於等級資料或非線性單調關係。 |
| 信賴區間帶 | Confidence band | 環繞在迴歸線周圍的區間範圍帶,呈現迴歸線在不同自變項數值下的估計誤差。 |