第四章:離散機率分布 (Discrete Probability Distributions)
4.1 導言與隨機變項
同學們,在前面的章節中,我們學會了什麼是機率,也探討了臨床篩檢中的不確定性。但是,每次做醫學研究,我們拿到的都是各式各樣的數據——有時是「患者是否康復」(是/否),有時是「患者的存活天數」(天數),有時是「急診室送進來的車禍傷患數」(人數)。
在統計學上,我們需要一個「數學橋樑」把這些真實世界的觀測結果與機率聯繫起來。這個橋樑就叫做隨機變項 (random variable)。
隨機變項並不是一個固定數值的變數,而是一個將隨機試驗的結果對應到數值的函數。一般我們用大寫字母(如 \(X\))表示隨機變項本身,用小寫字母(如 \(x\))表示它具體取出的某個數值。
隨機變項主要可以分成兩大家族:
- 離散隨機變項 (discrete random variable):
- 特徵:變項可以取值的個數是有限個,或者「可數的」無限個。通常是整數。
- 醫學例子:一家醫院裡今天出生的新生兒個數 \(X \in \{0, 1, 2, \dots\}\)、某藥物的副作用症狀個數。
- 連續隨機變項 (continuous random variable):
- 特徵:變項可以在某個實數區間內取任意值。個數是不可數的。
- 醫學例子:患者的血壓、體重、手術時間。這些數值需要精確的測量儀器,可以有無限多個小數點。
本章,我們將全神貫注在第一大成員——離散機率分布上。
4.2 離散隨機變項的分布特徵
當我們想描述一個離散隨機變項 \(X\) 的脾氣時,有兩個核心概念是必須掌握的:
4.2.1 機率質量函數 (Probability Mass Function, PMF)
這是一個幫每一個可能的取值 \(x\) 指派其發生機率的函數,記作 \(P(X = x)\) 或 \(p(x)\)。 它必須遵守兩大憲法:
- 每一個點的機率都不能是負數,且不能大於 1: \(0 \le P(X=x) \le 1\)
- 所有可能取值的機率相加必須剛好等於 1: \(\sum_{\text{all } x} P(X=x) = 1\)
4.2.2 期望值 (Expected Value)
期望值 \(E(X)\) 就是當試驗重複無數次之後,這個隨機變項的長期平均值。 計算公式是把每個可能的值乘以它發生的機率,然後全部加起來:
\[E(X) = \mu = \sum x P(X=x)\]
💡 教授的診間比喻: 假設有一種輕微手術,有 80% 的患者完全沒有併發症(併發症數 \(X = 0\)),有 15% 的人有 1 個輕微併發症(\(X = 1\)),有 5% 的人有 2 個併發症(\(X = 2\))。 請問一位病患預期會遇到的併發症個數(期望值)是多少? \[E(X) = 0 \times 0.80 + 1 \times 0.15 + 2 \times 0.05 = 0.15 + 0.10 = 0.25 \text{ 個}\] 雖然沒有任何一個病人的併發症個數會是「0.25 個」(你不可能切出 1/4 個倂發症!),但這個期望值告訴醫師:平均而言,每 100 位動這種手術的病人,總共會出現 25 個併發症。
4.2.3 變異數 (Variance)
離散隨機變項的變異數 \(Var(X)\) 衡量的是這些取值圍繞在期望值周圍的波動程度:
\[Var(X) = \sigma^2 = E[(X - E(X))^2] = \sum (x - \mu)^2 P(X=x)\]
4.3 二項分布:成敗二分法
在臨床研究中,最常見的狀況就是「投藥後,病人要么好了,要么沒好」;「手術後,病人要么活著,要么死了」。這種只有兩種可能結果的單次試驗,在統計學上叫做白努利試驗 (Bernoulli trial)。
如果我們進行了 \(n\) 次獨立的白努利試驗,每一次試驗成功的機率都是固定的 \(p\)(失敗機率為 \(1-p\))。此時,這 \(n\) 次試驗中「成功次數」\(X\) 的機率分布,就稱為二項分布 (binomial distribution),記作 \(X \sim B(n, p)\)。
4.3.1 排列與組合的快速複習
要計算二項分布的機率,我們必須知道在 \(n\) 次試驗中,出現 \(k\) 次成功的不同組合方式有多少種。我們使用組合 (combination) 公式:
\[\binom{n}{k} = C^n_k = \frac{n!}{k!(n-k)!}\]
4.3.2 二項分布的機率質量函數 (PMF)
在 \(n\) 次試驗中,成功次數剛好為 \(k\) 次的機率為:
\[P(X = k) = \binom{n}{k} p^k (1-p)^{n-k}, \quad k = 0, 1, 2, \dots, n\]
- 期望值: \(E(X) = np\)
- 變異數: \(Var(X) = np(1-p)\)
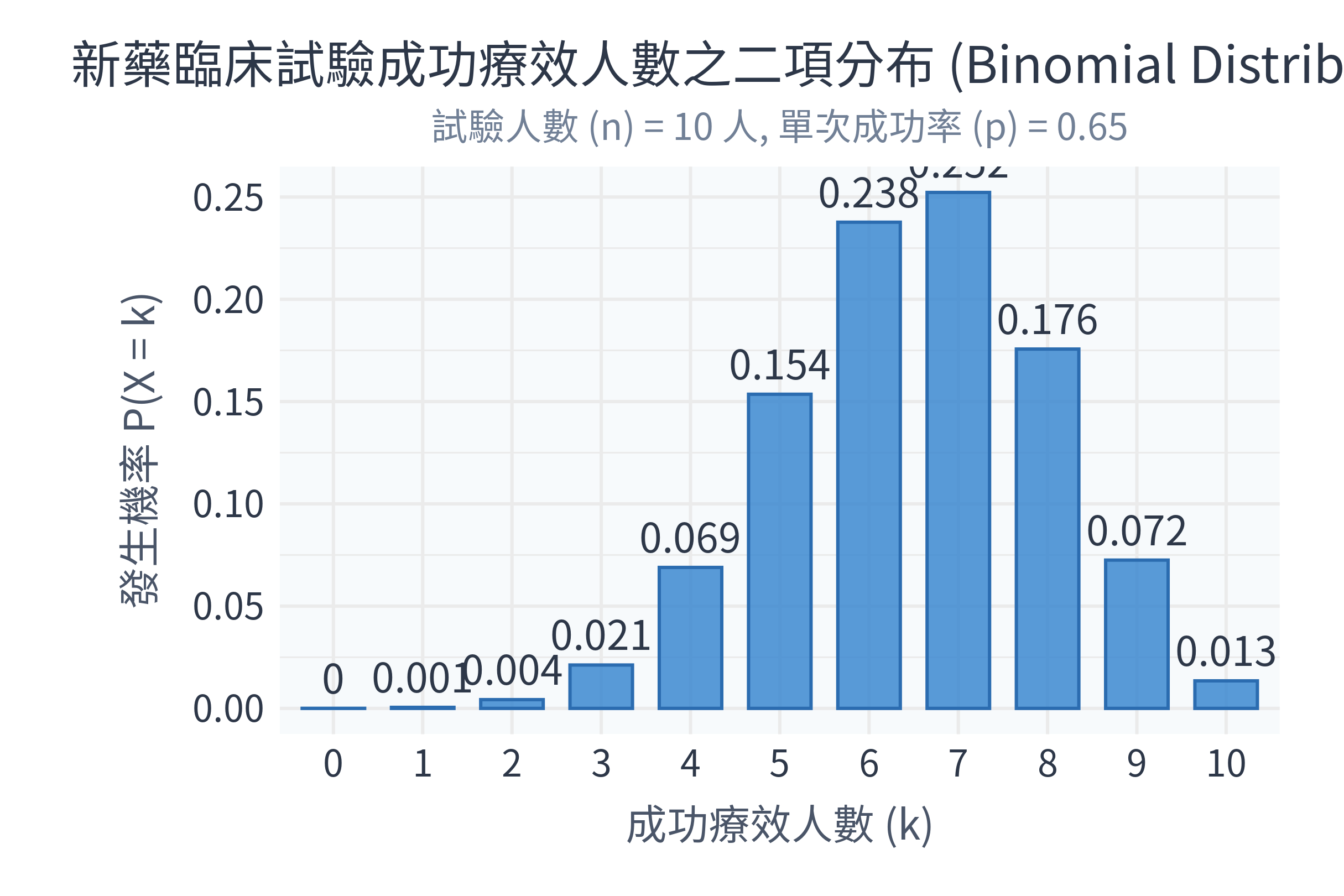
💊 新藥試驗例子: 假設某種新感冒藥的治癒率為 65% (\(p = 0.65\))。今天有 10 位獨立患者服用此藥 (\(n = 10\))。 請問這 10 人中「剛好有 7 人被治癒」的機率是多少? \[P(X = 7) = \binom{10}{7} (0.65)^7 (0.35)^3\] 其中 \(\binom{10}{7} = \frac{10!}{7!3!} = 120\)。 \[P(X = 7) = 120 \times 0.04902 \times 0.042875 \approx 0.2522 \text{ (25.2\%)}\] 平均而言,這 10 位患者中預期會被治癒的人數為 \(E(X) = 10 \times 0.65 = 6.5\) 人。
4.4 卜瓦松分布:罕見事件的魔咒
二項分布適合用在「有固定總試驗次數 \(n\)」的場景。但如果在醫學研究中,我們想觀察的是「在一段時間或空間內,某個罕見事件發生的次數」,那該怎麼辦?
例如:
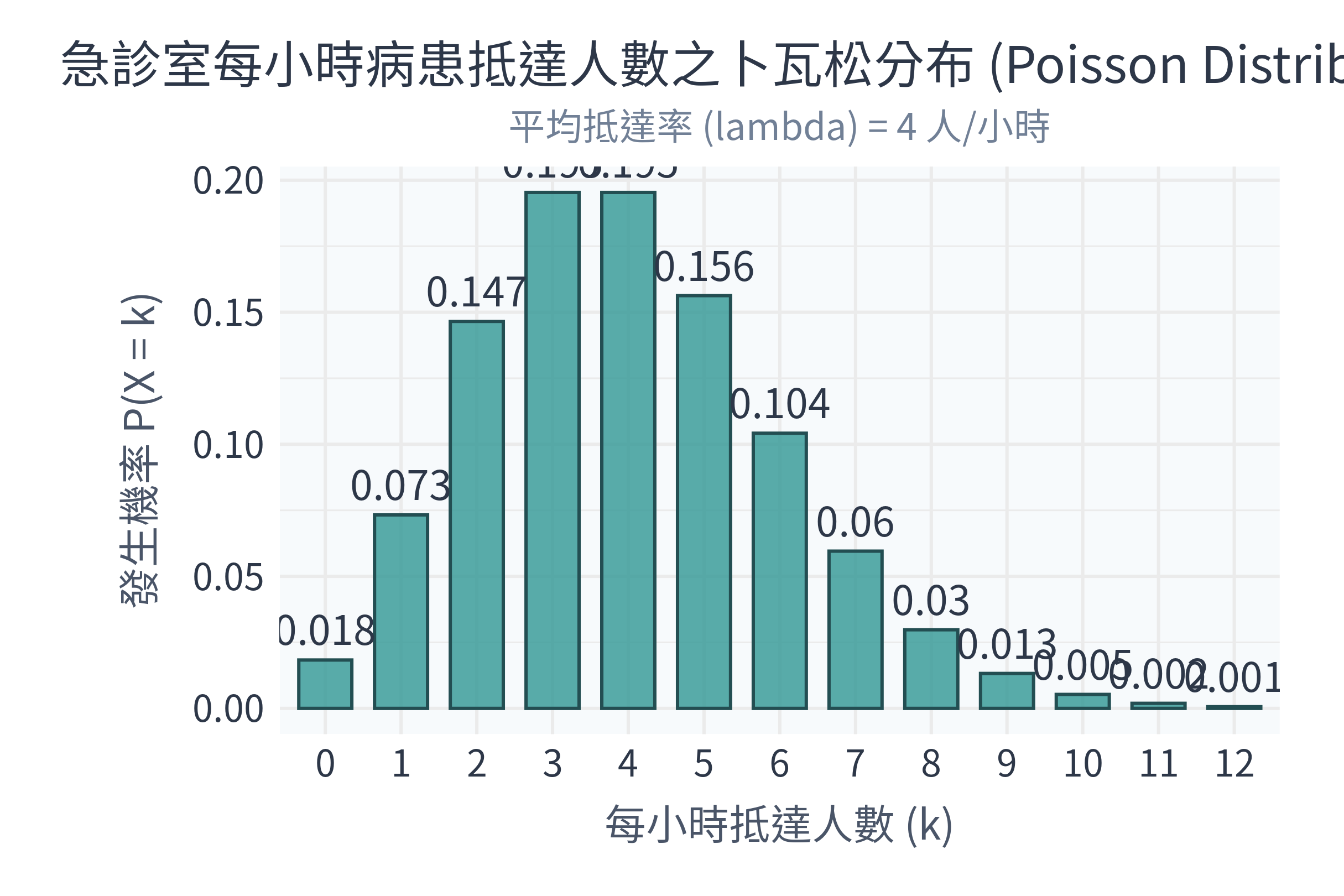
- 一家大型醫學中心急診室,平均每小時會送進來 4 位急診患者。請問下一個小時剛好送來 6 人的機率是多少?
- 某個十萬人的社區中,去年發生了 3 例罕見腦瘤。請問今年發生 0 例的機率是多少?
這類事件的特點是:潛在的「試驗次數」極大(甚至趨近無限大),但單次事件發生的機率極小。此時,我們使用卜瓦松分布 (Poisson distribution),記作 \(X \sim \text{Poisson}(\lambda)\)。
其中 \(\lambda\)(Lambda)代表在該時間/空間區間內,事件發生的平均次數(期望值)。
4.4.1 卜瓦松分布的機率質量函數 (PMF)
事件在指定區間內發生 \(k\) 次的機率為:
\[P(X = k) = \frac{\lambda^k e^{-\lambda}}{k!}, \quad k = 0, 1, 2, \dots\]
這裡的 \(e\) 是自然常數(約等於 2.71828)。 卜瓦松分布最神奇也最容易記的特徵就是:
- 期望值: \(E(X) = \lambda\)
- 變異數: \(Var(X) = \lambda\) (期望值跟變異數一模一樣,就是這麼任性!)
4.4.2 二項分布之卜瓦松近似
當二項分布的 \(n\) 非常大(例如 \(n \ge 100\)),且 \(p\) 非常小(例如 \(p \le 0.01\))時,直接計算二項分布會非常痛苦。此時我們可以令 \(\lambda = np\),用卜瓦松分布來非常精準地逼近二項分布的計算結果。
4.5 實戰演練:使用 R 進行二項與卜瓦松分布建模
現在,我們打開 RStudio,利用 R 的內建機率函數,來幫上述的兩個臨床情境進行建模,並繪製出精美的機率質量函數分布圖。
4.5.1 R 語言中的機率四大函數前綴
在 R 中,對於任何分布(如 binom, pois),都有四個核心函數:
d開頭 (density/probability):計算單點機率 \(P(X = k)\),如dbinom(),dpois()。p開頭 (probability cumulative):計算累積機率 \(P(X \le k)\),如pbinom(),ppois()。q開 quarter (quantile):給定累積機率,反查隨機變數值。r開頭 (random):隨機抽樣模擬,如rbinom(),rpois()。
4.5.2 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# ==========================================
# 情境一:新藥治療成功人數的二項分布 B(10, 0.65)
# ==========================================
n_binom <- 10
p_binom <- 0.65
x_binom <- 0:10
prob_binom <- dbinom(x_binom, size = n_binom, prob = p_binom)
df_binom <- data.frame(
Successes = factor(x_binom),
Probability = prob_binom
)
p1 <- ggplot(df_binom, aes(x = Successes, y = Probability)) +
geom_col(fill = "#3182ce", color = "#2b6cb0", alpha = 0.8, width = 0.7) +
geom_text(aes(label = round(Probability, 3)), vjust = -0.5, size = 6.2, color = "#2d3748", family = "Noto Sans CJK TC") +
labs(
title = "新藥臨床試驗成功療效人數之二項分布 (Binomial Distribution)",
subtitle = paste("試驗人數 (n) = 10 人, 單次成功率 (p) = 0.65"),
x = "成功療效人數 (k)",
y = "發生機率 P(X = k)"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請更換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
ggsave("figs/binomial_pmf.png", plot = p1, width = 8.1, height = 5.4, dpi = 300)
# ==========================================
# 情境二:急診室每小時病患抵達人數的卜瓦松分布 Poisson(4)
# ==========================================
lambda_pois <- 4
x_pois <- 0:12
prob_pois <- dpois(x_pois, lambda = lambda_pois)
df_pois <- data.frame(
Arrivals = factor(x_pois),
Probability = prob_pois
)
p2 <- ggplot(df_pois, aes(x = Arrivals, y = Probability)) +
geom_col(fill = "#319795", color = "#234e52", alpha = 0.8, width = 0.7) +
geom_text(aes(label = round(Probability, 3)), vjust = -0.5, size = 6.2, color = "#2d3748", family = "Noto Sans CJK TC") +
labs(
title = "急診室每小時病患抵達人數之卜瓦松分布 (Poisson Distribution)",
subtitle = paste("平均抵達率 (lambda) =", lambda_pois, "人/小時"),
x = "每小時抵達人數 (k)",
y = "發生機率 P(X = k)"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請更換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
ggsave("figs/poisson_pmf.png", plot = p2, width = 8.1, height = 5.4, dpi = 300)4.5.3 統計圖表解讀
當你執行完上述程式後,figs/ 資料夾下會生成以下兩張離散分布圖表:
數據診斷分析:
- 二項分布解讀:從左圖可以看出,當 \(n=10, p=0.65\) 時,最有可能的成功治療人數是 7 人(機率約 25.2%),其次是 6 人(23.8%)與 8 人(17.6%)。這與我們期望值 \(E(X) = 6.5\) 人的理論分析完美契合。
- 卜瓦松分布解讀:從右圖可以看出,在平均每小時有 4 位病患抵達的急診室中,單個小時內「剛好來 3 人」或「剛好來 4 人」的機率最高(皆約為 19.5%)。雖然平均是 4 人,但有時候忙起來,一小時來 8 人以上的機率依然存在,這也提醒了急診醫學科主管必須保留一定的醫療彈性彈性!
4.6 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 隨機變項 | Random variable | 將隨機試驗之結果對應到具體實數數值的數學函數。 |
| 離散隨機變項 | Discrete random variable | 取值個數有限或屬於可數無限個(通常是整數)的隨機變項。 |
| 連續隨機變項 | Continuous random variable | 取值可以在某實數區間內任意取值的隨機變項。 |
| 機率質量函數 | Probability mass function (PMF) | 給定離散隨機變項各別可能取值之精確發生機率的函數。 |
| 期望值 | Expected value | 隨機變項無限次重複試驗後的長期平均值,即以機率為權重的加權平均。 |
| 變異數 | Variance | 衡量隨機變項取值與期望值之間偏差平方和的加權平均。 |
| 白努利試驗 | Bernoulli trial | 只有兩種可能結果(成功/失敗)的單次獨立隨機試驗。 |
| 排列 | Permutation | 從物件中取出部分進行有順序之排列的方式種類數。 |
| 組合 | Combination | 從物件中取出部分且不考慮順序之組合的種類數。 |
| 二項分布 | Binomial distribution | 進行 n 次獨立白努利試驗中,成功次數的機率分布。 |
| 卜瓦松分布 | Poisson distribution | 描述在固定時間或空間區間內,某罕見隨機事件發生次數的機率分布。 |
| 卜瓦松逼近 | Poisson approximation | 當二項分布之試驗次數 n 極大且成功率 p 極小時,以卜瓦松分布代替計算的近似法。 |