第五章:連續機率分布 (Continuous Probability Distributions)
5.1 導言與連續型分布概念
同學們,在上一章我們學習了如何計算「可數的」離散事件機率。但是,在醫學與公衛實務中,我們測量的許多關鍵指標都是連續型的。
例如:
- 新生兒的出生體重(可能從 1500g 到 4500g,可以是 3205.2g、3205.24g 等無限多個可能值)。
- 患者服用退燒藥後的降溫時間。
- 血液中某種抗原的濃度。
對於這些連續隨機變項 (continuous random variable),有一個非常奇特卻很重要的統計學常識: 「在連續隨機變項中,它剛好等於某一個精確數值的機率是 0。」
💡 教授的思考挑戰: 請問一個新生兒出生體重「剛好、精確地等於 3200.0000000000... 公克」的機率是多少? 因為體重可以用無限精細的秤來量,分母(可能數值)是無限大。任何數值除以無限大,答案就是 0。 因此,我們不能問 \(P(X = 3200)\)。我們必須改問一個區間機率,例如:「體重落在 3199 公克到 3201 公克之間的機率是多少?」或「體重低於 2500 公克的機率是多少?」
為了描述連續隨機變項的機率,我們不使用機率質量函數,而是使用機率密度函數 (probability density function, PDF,記作 \(f(x)\))。
機率密度函數 (PDF):一條描繪數據分佈形狀的曲線。曲線下方在某個區間(例如 \(a\) 到 \(b\))的面積,就代表變項落在該區間的機率: \[P(a \le X \le b) = \text{曲線在 } a \text{ 到 } b \text{ 之間的面積} = \int_a^b f(x) dx\] (別怕,我們不用手算微積分,R 會幫我們搞定!)
累積分布函數 (cumulative distribution function, CDF,記作 \(F(x)\)):代表小於或等於某個數值 \(x\) 的累積機率: \[F(x) = P(X \le x)\]
5.2 常態分布:生物統計學的「帝王」
如果統計學界要舉辦一場選美比賽,那麼常態分布 (normal distribution) 絕對會以無爭議的高票奪冠。它是所有連續分布中最重要、最常用的一個,其外形就像是一口左右對稱的鐘,因此又被稱為鐘形曲線 (bell curve)。
5.2.1 常態分布的數學定義
如果一個連續隨機變項 \(X\) 服從常態分布,其平均值為 \(\mu\),標準差為 \(\sigma\),我們記作 \(X \sim N(\mu, \sigma^2)\)。它的 PDF 數學公式為:
\[f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2}\]
這個公式看起來很嚇人(裡面有圓周率 \(\pi\) 還有自然常數 \(e\)),但別慌!你只需要記住兩個控制它外貌的「遙控器」:
- 平均數 (\(\mu\)):控制這口鐘在 X 軸上的中心位置。
- 標準差 (\(\sigma\)):控制這口鐘的胖瘦(離散程度)。標準差愈大,鐘就愈扁愈寬;標準差愈小,鐘就愈尖愈窄。
5.2.2 常態分布的經驗法則 (Empirical Rule)
不論常態分布的 \(\mu\) 和 \(\sigma\) 是多少,它都遵守非常有名的 68-95-99.7 法則:
- 約有 68.3% 的數據,會落在平均數正負 1 個標準差之內(\(\mu \pm 1\sigma\))。
- 約有 95.4%(臨床上常簡化為 95%)的數據,會落在平均數正負 2 個標準差之內(\(\mu \pm 2\sigma\),更精確地說是 \(\mu \pm 1.96\sigma\))。
- 約有 99.7% 的數據,會落在平均數正負 3 個標準差之內(\(\mu \pm 3\sigma\))。
|
.-"'"-.
.' | '.
.' | '.
.' | '.
.' | '.
.' | | | '.
/ | | | \
| | | | |
-+------|-------|-------|------+--
-1σ μ +1σ
|<--- 68.3% --->|5.3 標準常態分布與標準化
因為世界上有無限多種不同的常態分布(例如:新學員身高分布、收縮壓分布、血糖分布),我們不可能為每一種分布都去印一張機率表。
為了解決這個問題,統計學家把所有的常態分布通通「格式化」成一個標準規格——標準常態分布 (standard normal distribution)。
- 標準常態分布 的平均數為 0,標準差為 1,通常用字母 \(Z\) 表示: \[Z \sim N(0, 1)\]
5.3.1 標準化公式:換算你的 Z 分數 (Z-score)
要把任何一個常態隨機變項 \(X\) 轉換成標準常態隨機變項 \(Z\),我們使用標準化 (standardization) 公式:
\[Z = \frac{X - \mu}{\sigma}\]
這個算出來的 \(Z\) 值,代表著「你的數值距離平均值有幾個標準差的距離」。
- 如果 \(Z = 1.5\),代表你的數值比平均值高出 1.5 個標準差。
- 如果 \(Z = -0.8\),代表你的數值比平均值低了 0.8 個標準差。
👶 臨床案例: 假設足月新生兒的出生體重服從常態分布,平均值 \(\mu = 3200\)g,標準差 \(\sigma = 450\)g。 今天有一位小寶寶出生體重為 \(X = 2500\)g。請問他的體重標準化後的 \(Z\) 分數是多少? \[Z = \frac{2500 - 3200}{450} = \frac{-700}{450} \approx -1.56\] 這代表他的出生體重比全體平均低了 1.56 個標準差。
5.4 常態分布逼近與連續性修正
常態分布不僅能描述連續型數據,它還能作為離散分布(如二項分布、卜瓦松分布)在樣本數很大時的「超級替身」。
5.4.1 常態逼近二項分布
當二項分布 \(B(n, p)\) 的試驗次數 \(n\) 很大時,我們可以使用常態分布 \(N(np, np(1-p))\) 來估算機率。
- 黃金適用條件: \(np \ge 5\) 且 \(n(1-p) \ge 5\)。
5.4.2 連續性修正 (Continuity Correction)
當我們用一個連續的曲線(常態分布)去逼近離散的柱狀圖(二項分布)時,會遇到格子對不齊的狀況。
例如,二項分布中的 \(X=10\) 是一個寬度為 1 的長條(從 9.5 到 10.5)。如果我們直接用常態分布計算 \(P(X \ge 10)\),會漏掉 9.5 到 10 之間的那半個長條。
為了彌補這個空隙,我們必須進行連續性修正 (continuity correction):
- 計算 \(P(X \ge k)\) 時,常態近似調整為 \(P(Y \ge k - 0.5)\)
- 計算 \(P(X \le k)\) 時,常態近似調整為 \(P(Y \le k + 0.5)\)
- 計算 \(P(X = k)\) 時,常態近似調整為 \(P(k - 0.5 \le Y \le k + 0.5)\) (其中 \(Y\) 是服從常態分布的隨機變項)
5.5 實戰演練:新生兒出生體重的常態分布與機率計算
現在,讓我們打開 RStudio,來計算剛才提到的新生兒出生體重機率,並利用 ggplot2 畫出一張非常漂亮且符合學術水準的常態分佈密度曲線,並將「低出生體重區」(小於 2500 公克)標記出來。
5.5.1 RStudio 操作說明
- 打開 RStudio。
- 點選左上角新建 R Script。
- 貼入以下程式碼並執行。
5.5.2 R 程式碼實作
# 1. 載入 ggplot2 繪圖套件
library(ggplot2)
# 2. 定義常態分佈參數(足月新生兒出生體重平均 3200g, 標準差 450g)
mu <- 3200
sigma <- 450
# 3. 使用 R 的 pnorm() 函數計算出生體重低於 2500g 的機率
# pnorm(q, mean, sd) 可以直接計算 P(X <= q) 的累積機率
prob_low <- pnorm(2500, mean = mu, sd = sigma)
cat("--- 新生兒出生體重分析結果 ---\n")
cat("出生體重低於 2500g (低出生體重) 的機率為:", round(prob_low * 100, 2), "%\n")
cat("-------------------------------\n")
# 4. 生成繪製常態曲線所需的 X 與 Y 座標數據
x_vals <- seq(mu - 4 * sigma, mu + 4 * sigma, length.out = 1000)
y_vals <- dnorm(x_vals, mean = mu, sd = sigma) # dnorm() 計算機率密度 PDF 值
df_norm <- data.frame(Weight = x_vals, Density = y_vals)
# 5. 篩選出低於 2500g 的區域數據以利塗色
df_shaded <- subset(df_norm, Weight < 2500)
# 6. 使用 ggplot2 繪製常態分布圖
p_norm <- ggplot(df_norm, aes(x = Weight, y = Density)) +
geom_line(color = "#2b6cb0", linewidth = 1.2) +
# 塗色低出生體重區域
geom_area(data = df_shaded, aes(y = Density), fill = "#e53e3e", alpha = 0.5) +
geom_vline(xintercept = 2500, linetype = "dashed", color = "#e53e3e", linewidth = 0.8) +
# 加入圖表文字註解
annotate("text", x = 2100, y = 0.0002,
label = paste0("低出生體重區\n(< 2500g)\n機率 = ", round(prob_low * 100, 2), "%"),
size = 6.2, color = "#9b2c2c", family = "Noto Sans CJK TC", fontface = "bold") +
annotate("text", x = 3200, y = 0.0005,
label = paste0("正常分佈中心\n平均值 = ", mu, "g\n標準差 = ", sigma, "g"),
size = 6.2, color = "#2d3748", family = "Noto Sans CJK TC") +
labs(
title = "新生兒出生體重之常態分布 (Normal Distribution)",
subtitle = "呈現低出生體重界限與對應機率範圍",
x = "出生體重 Birth Weight (grams)",
y = "機率密度 Probability Density"
) +
theme_minimal(base_family = "Noto Sans CJK TC", base_size = 15) + # Windows 請替換為 Microsoft JhengHei
theme(
plot.title = element_text(size = 22, hjust = 0.5, color = "#2d3748"),
plot.subtitle = element_text(size = 16, hjust = 0.5, color = "#718096"),
axis.title = element_text(size = 18, color = "#4a5568"),
axis.title.x = element_text(margin = margin(t = 10)),
axis.title.y = element_text(margin = margin(r = 12)),
axis.text = element_text(size = 16, color = "#2d3748"),
panel.background = element_rect(fill = "#f7fafc", color = NA),
plot.background = element_rect(fill = "white", color = NA),
plot.margin = margin(20, 28, 20, 54)
)
# 顯示並儲存圖檔
print(p_norm)
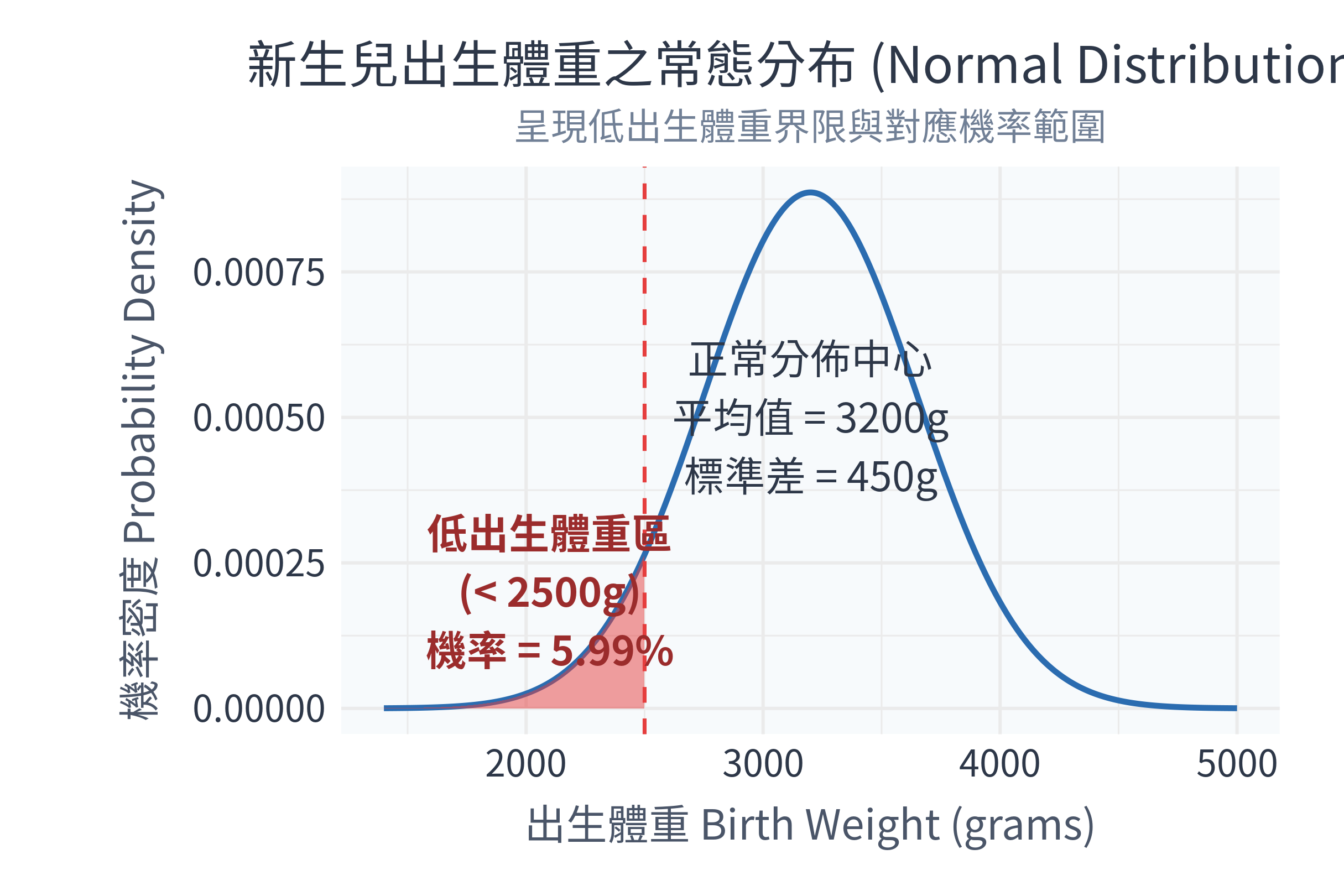
ggsave("figs/normal_birthweight.png", plot = p_norm, width = 8.1, height = 5.4, dpi = 300)5.5.3 統計圖表解讀
在 R 中執行程式後,控制台會輸出:
--- 新生兒出生體重分析結果 ---
出生體重低於 2500g (低出生體重) 的機率為: 5.99 %
------------------------------同時,figs/ 資料夾下會生成以下圖表:
數據診斷分析:
- 機率臨床解讀:根據我們設定的常態分布模型,約有 5.99% 的新生兒出生時體重會低於 2500 公克(在臨床上被定義為低出生體重,low birth weight)。這說明了如果一家婦產科診所預期一個月有 200 位寶寶誕生,大約會有 12 位寶寶需要特別送入保溫箱觀察。
- Z分數對照:小於 2500g 對應的 \(Z\) 分數為 \(-1.56\)。查閱標準常態分佈表,我們同樣能得到 \(P(Z \le -1.56) \approx 0.0594\) 的結果,與 R 的精確計算高度契合。
5.6 本章名詞對照表 (Glossary)
| 中文名稱 | 英文名稱 | 定義與說明 |
|---|---|---|
| 機率密度函數 | Probability density function (PDF) | 描述連續型隨機變項在各點相對可能性的函數,曲線下面積代表機率。 |
| 累積分布函數 | Cumulative distribution function (CDF) | 隨機變項小於或等於某一特定數值之累積機率的函數。 |
| 常態分布 | Normal distribution | 統計學中最核心的對稱鐘形機率分布,由平均數與標準差決定其外觀。 |
| 標準常態分布 | Standard normal distribution | 平均數為 0 且標準差為 1 的特殊常態分布,常以 Z 表示。 |
| 經驗法則 | Empirical rule | 常態分布中,數據落在正負 1, 2, 3 個標準差範圍的比例法則 (68-95-99.7)。 |
| 標準化 | Standardization | 將一般常態分布隨機變項減去平均數後除以標準差,以轉換為 Z 分數的過程。 |
| Z 分數 | Z-score | 代表某數值偏離平均數多少個標準差大小的數值。 |
| 連續性修正 | Continuity correction | 當用連續型分布(如常態分布)逼近離散型分布時,對邊界進行正負 0.5 調整的修正法。 |
| 常態逼近 | Normal approximation | 在特定條件(如大樣本)下,使用常態分布替代二項分布或卜瓦松分布進行計算的近似法。 |
| 低出生體重 | Low birth weight (LBW) | 嬰兒出生時體重低於 2500 公克的臨床定義。 |